Proactive problem management: Langkah awal sebelum insiden terjadi

Bayangkan sebuah layanan digital yang berjalan lancar tiap hari. Tiba-tiba, pengguna mengeluh karena layanan jadi sering crash dan aksesnya melambat. Hal ini tidak hanya menganggu produktivitas, tetapi juga bisa memengaruhi kepercayaan pelanggan terhadap layanan IT.
Padahal, gangguan semacam ini bisa dicegah. Dengan bersikap proaktif alih-alih reaktif, Anda bisa memprediksi dan mencegah masalah lebih awal. Inilah yang disebut dengan proactive problem management. Tujuannya untuk menemukan potensi masalah sejak dini, mencegah insiden berulang, dan memastikan kualitas layanan tetap stabil.
Di blog ini, Anda bisa mempelajari lebih lanjut tentang proactive problem management. Mulai dari pengertian, perbedaannya dengan reactive problem management, manfaat, dan cara menerapkannya. Simak selengkapnya!
Apa itu proactive problem management?
Dalam kerangka ITIL (Information Technology Infrastructure Library), problem management adalah salah satu praktik inti di IT Service Management (ITSM). Problem management bertujuan untuk mengurangi dampak insiden IT dengan mencari akar penyebab masalah dan mencegah insiden berulang.
Proactive problem management merupakan salah satu pendekatan lanjutan dari problem management. Sama seperti namanya, pendekatan ini bersifat proaktif dengan fokus mencari dan menyelesaikan masalah sebelum masalah itu berubah menjadi insiden nyata. Jadi, tim IT tidak menunggu ada masalah yang datang baru sibuk memperbaiki, melainkan "menjemput bola" dengan mengidentifikasi potensi masalah terlebih dahulu.
Proactive problem management sejalan dengan prinsip continual service improvement (CSI) di ITIL. Ini karena proactive problem management melakukan review berkala, mengidentifikasi masalah sebelum berubah menjadi insiden, dan memperbaiki proses IT supaya masalah serupa tidak muncul lagi. Hasilnya, layanan yang diberikan lebih berkualitas dan berkelanjutan.
Apa perbedaan proactive dan reactive problem management?
Kebalikan dari proactive problem management adalah reactive problem management. Jika proactive problem management berfokus pada pencarian dan analisis masalah sebelum menganggu layanan, maka reactive problem management justru baru mulai bergerak memperbaiki masalah setelah terjadi. Bisa dibilang, reactive problem management bertindak lebih belakangan daripada proactive problem management.
Sebenarnya, baik proactive maupun reactive problem management, keduanya sama-sama penting dalam operasional IT. Organisasi tetap membutuhkan reactive problem management karena tidak semua insiden bisa terdeteksi sejak awal. Namun, seiring bertambahnya pengalaman dan kematangan layanan, organisasi biasanya beralih dari reactive ke proactive problem management. Peralihan ini dilakukan karena hasilnya dapat membuat layanan lebih stabil, hemat waktu, dan mengurangi risiko downtime.
Secara sederhana, perbedaan proactive dan reactive problem management dapat disimpulkan menjadi tabel berikut:
Aspek | Reactive Problem Management | Proactive Problem Management |
Waktu | Setelah masalah/insiden muncul | Sebelum masalah muncul |
Fokus utama | Mengatasi akar masalah dari insiden yang sudah terjadi | Mendeteksi potensi masalah dari data log, monitoring, atau insiden lama |
Contoh kasus | Saat server down, tim akan mencari penyebab lalu memperbaiki | Tim mengecek log secara rutin untuk menemukan tanda-tanda error. Error akan diperbaiki sebelum menyebabkan server down |
Kelebihan | - Mudah diterapkan di tahap awal - Tim bisa belajar dari masalah nyata | - Mencegah insiden besar terjadi - Meningkatkan stabilitas dan keandalan layanan |
Kekurangan | - Bisa membuat downtime lebih lama - Lebih reaktif, terkadang menimbulkan panik | - Butuh tim dengan skill analisis yang kuat - Susah diukur manfaatnya karena masalah belum terjadi |
Cocok untuk | Organisasi yang baru mulai menerapkan problem management | Organisasi yang sudah matang dalam manajemen layanan IT |
Apa saja manfaat proactive problem management?
Proactive problem management punya beberapa manfaat bagi organisasi, yaitu:
Mencegah insiden besar terjadi: Dengan deteksi dan penanganan dini, organisasi dapat mengurangi risiko terjadinya insiden besar yang bisa menganggu operasional bisnis.
Menjaga kualitas layanan: Jika masalah ditangani langsung dari akar penyebabnya, gangguan layanan bisa dihindari sehingga kualitas layanan tetap stabil dan user tidak merasakan dampaknya.
Mengurangi downtime: Proactive problem management membantu identifikasi dan resolusi masalah sebelum berdampak lebih besar. Hal ini bisa mengurangi downtime dan meningkatkan availability sistem.
Meningkatkan efisiensi: Karena proactive problem management membuat tim IT menangani masalah sebelum menjadi lebih besar, mereka tidak perlu kerepotan seperti saat menangani masalah yang sudah terjadi. Hal ini membuat tugas tim IT lebih efisien dan mereka bisa fokus ke tugas lain yang lebih strategis.
Menghemat biaya: Masalah yang membesar bisa menimbulkan kerugian finansial bagi organisasi, baik itu berupa denda karena tidak patuh regulasi atau biaya perbaikan insiden.
Meningkatkan risk management: Dengan mendeteksi dan memitigasi masalah sejak awal, organisasi bisa mengurangi risiko sekaligus memastikan kepatuhan terhadap regulasi.
Memudahkan pengambilan keputusan: Penggunaan tool analitik dan monitoring pada proactive problem management bisa memberikan data yang diperlukan untuk mengambil keputusan berdasarkan data.
Bagaimana cara menerapkan proactive problem management?
Berdasarkan ITIL 4, problem management terbagi menjadi empat tahap utama, yaitu Problem Identification, Problem Control, Error Control, dan Problem Resolution and Closure. Masing-masing tahap ini memiliki tugas, tanggung jawab, dan aktivitas utamanya masing-masing.
1. Problem Identification (Identifikasi Masalah)
Di tahap ini, tim IT mengenali masalah yang berpotensi menimbulkan insiden. Tahap ini memiliki beberapa aktivitas utama, seperti:
Melakukan trend analysis dari data insiden dan log historis untuk mencari pola masalah berulang, misalnya login error, aplikasi crash, atau server overload. Dengan analisis ini, tim bisa tahu masalah mana yang harus diprioritaskan untuk dicegah agar tidak muncul lagi di masa depan.
Menggunakan tool monitoring real-time (SIEM, AIOps, observability) untuk mendeteksi anomali dan memberikan alert lebih awal. Bahkan, kini juga banyak tool monitoring yang juga bisa merekomendasikan remediasi otomatis.
Menjalankan risk assessment berkala untuk menemukan titik lemah di infrastruktur. Titik lemah yang dimaksud misalnya patch yang belum diinstal, konfigurasi yang salah, atau kapasitas penyimpanan yang hampir penuh. Dengan risk assessment berkala, tim bisa melakukan pencegah sebelum celah tersebut dieksploitasi.
Mengambil feedback dari user yang menggunakan langsung aplikasi.
Melakukan analisis menggunakan prinsip Pareto (80:20). Dari prinsip ini, Anda bisa tahu kalau sebagian besar insiden (katakanlah 80%) disebabkan oleh hanya sedikit masalah utama (sekitar 20%). Jadi, dengan fokus ke 20% penyebab terbesar, tim bisa menekan jumlah insiden jauh lebih efektif.
2. Problem Control (Pengendalian Masalah)
Pada tahap ini, tim mulai mengendalikan masalah yang telah teridentifikasi dengan menetapkan prioritas, melakukan investigasi dan analisis mendalam, serta mendokumentasikan hasilnya. Aktivitas yang biasa dilakukan dalam tahap problem control yaitu:
Melakukan root cause analysis (RCA) menggunakan teknik 5Whys atau Fishbone Diagram untuk menelusuri penyebab utama, bukan hanya gejala.
Menggunakan metrik dalam memantau kualitas layanan dan efisiensi proses. Metriknya misalnya jumlah insiden berulang atau MTTR. Dengan analisis metrik, tim bisa mengukur urgensi dan dampak sebuah masalah serta prioritasnya.
Menerapkan knowledge sharing dengan mendokumentasikan masalah dan solusi di KEDB (Known Error Database) atau sistem knowledge management. Tujuannya agar solusi bisa dipelajari lintas tim.
Melakukan kolaborasi lintas tim, seperti tim infrastruktur, aplikasi, keamanan, maupun operasional. Dengan kolaborasi, proses investigasi dan validasi solusi sementara bisa berlangsung lebih cepat.
3. Error Control (Pengendalian Error)
Tahap ini fokus pada mengelola error yang sudah terdokumentasi KEDB (Known Error Database). Tujuannya adalah memastikan setiap error yang sudah dikenali dievaluasi secara berkala untuk menemukan solusi permanen yang layak, sekaligus menguji workaround yang digunakan.
Biasanya, dalam mengendalikan error, Anda dapat melakukan:
Meninjau error dari KEDB secara berkala untuk mencari solusi permanen yang mungkin.
Menganalisis cost-benefit supaya solusi permanen yang diterapkan jelas secara biaya, risiko, dan manfaatnya. Jika hasil analisis ini positif, maka solusi bisa dilanjutkan ke tahap implementasi.
Meninjau error yang sudah diketahui untuk menilai dampaknya terhadap layanan.
4. Problem Resolution and Closure (Penyelesaian Masalah)
Tahap terakhir ini fokus pada implementasi solusi permanen untuk mengatasi akar masalah yang ada. Tujuannya untuk mencegah masalah tidak terjadi lagi di kemudian hari, mengembangkan solusi yang tepat, dan memastikan implementasi aman.
Aktivitas pada tahap terakhir ini yaitu:
Mengevaluasi opsi solusi, misalnya menerapkan patch software atau upgrade hardware. Dari pilihan yang ada, tim perlu memilih yang paling efektif serta berkelanjutan.
Melakukan testing di lingkungan staging sebelum diterapkan ke production, supaya solusi yang dipilih aman.
Menggunakan error control checklist untuk memvalidasi semua langkah perbaikan permanen sudah dijalankan dengan benar.
Menerapkan collaborative planning dengan melibatkan stakeholder terkait dalam merencanakan implementasi agar tidak menimbulkan risiko baru.
Mencatat solusi yang berhasil dan memasukkannya ke knowledge database sebagai bentuk pembelajaran.
Apa fitur yang perlu dimiliki dalam problem management software?
Salah satu cara untuk memudahkan penerapan proactive problem management adalah dengan menggunakan software. Namun, memilih software yang tepat bisa menjadi kendala bagi organisasi. Dari banyaknya software yang ada, organisasi perlu memilih problem management software dengan fitur-fitur berikut.
1. Root Cause Analysis
Fitur root causes analysis berfungsi untuk menganalisis akar masalah dari masalah dan mendokumentasikannya. Dengan fitur ini, organisasi bisa memahami mengapa masalah bisa terjadi dan menyediakan solusi yang tepat untuk permasalahan tersebut.
2. Prediksi cerdas berbasis AI
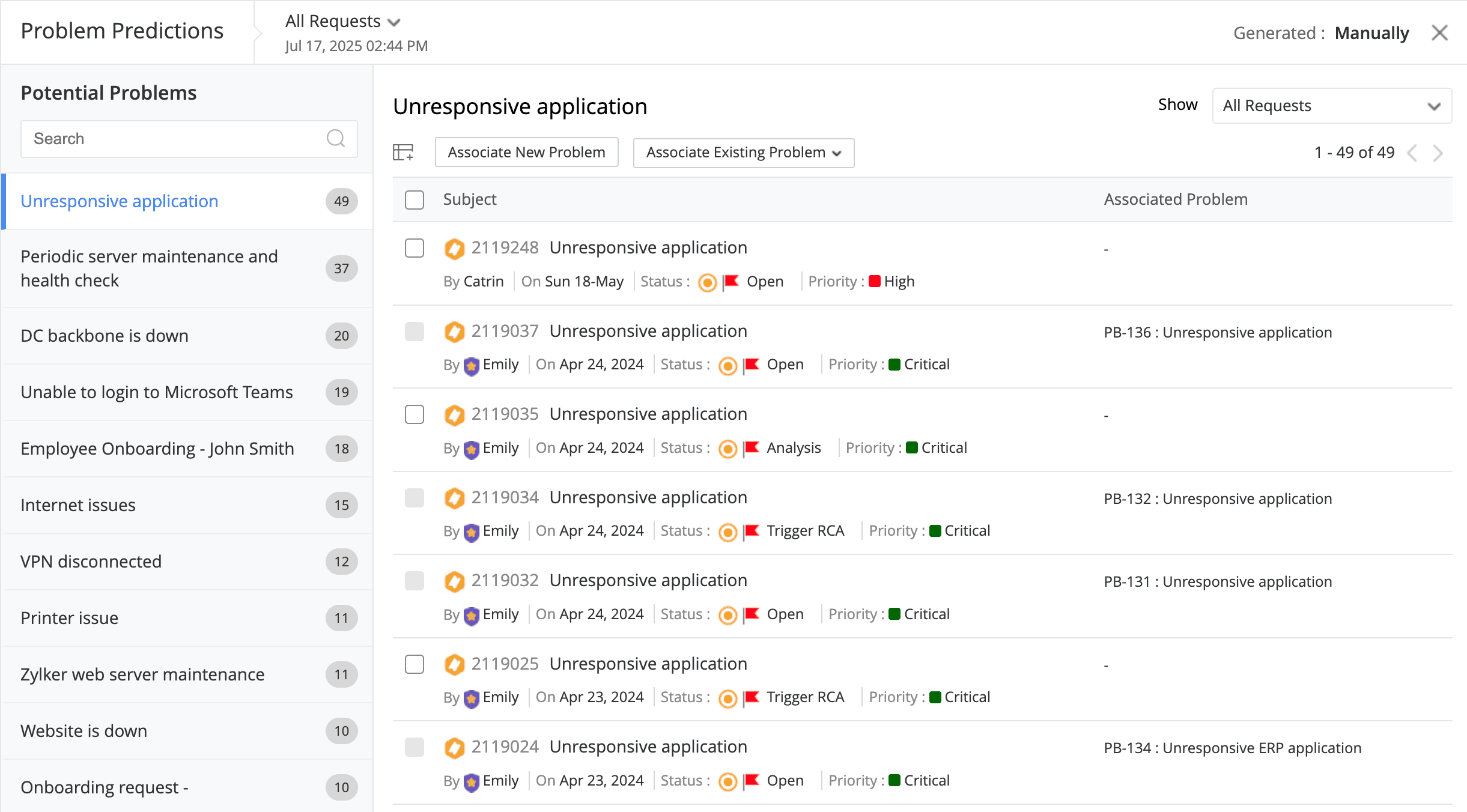
Belakangan ini, penggunaan AI dalam teknologi semakin meningkat. Begitu juga dengan problem management software yang memanfaatkan AI dalam bentuk fitur prediksi cerdas. Melalui fitur ini, tim bisa mengidentifikasi potensi masalah lebih cepat.
Zia adalah asisten AI dari ManageEngine ServiceDesk Plus yang mampu melakukan tugas ini. Zia bisa memberikan prediksi cerdas terkait masalah dan mengarahkan tiket masalah yang masuk ke teknisi yang tepat.
3. Visualisasi workflow
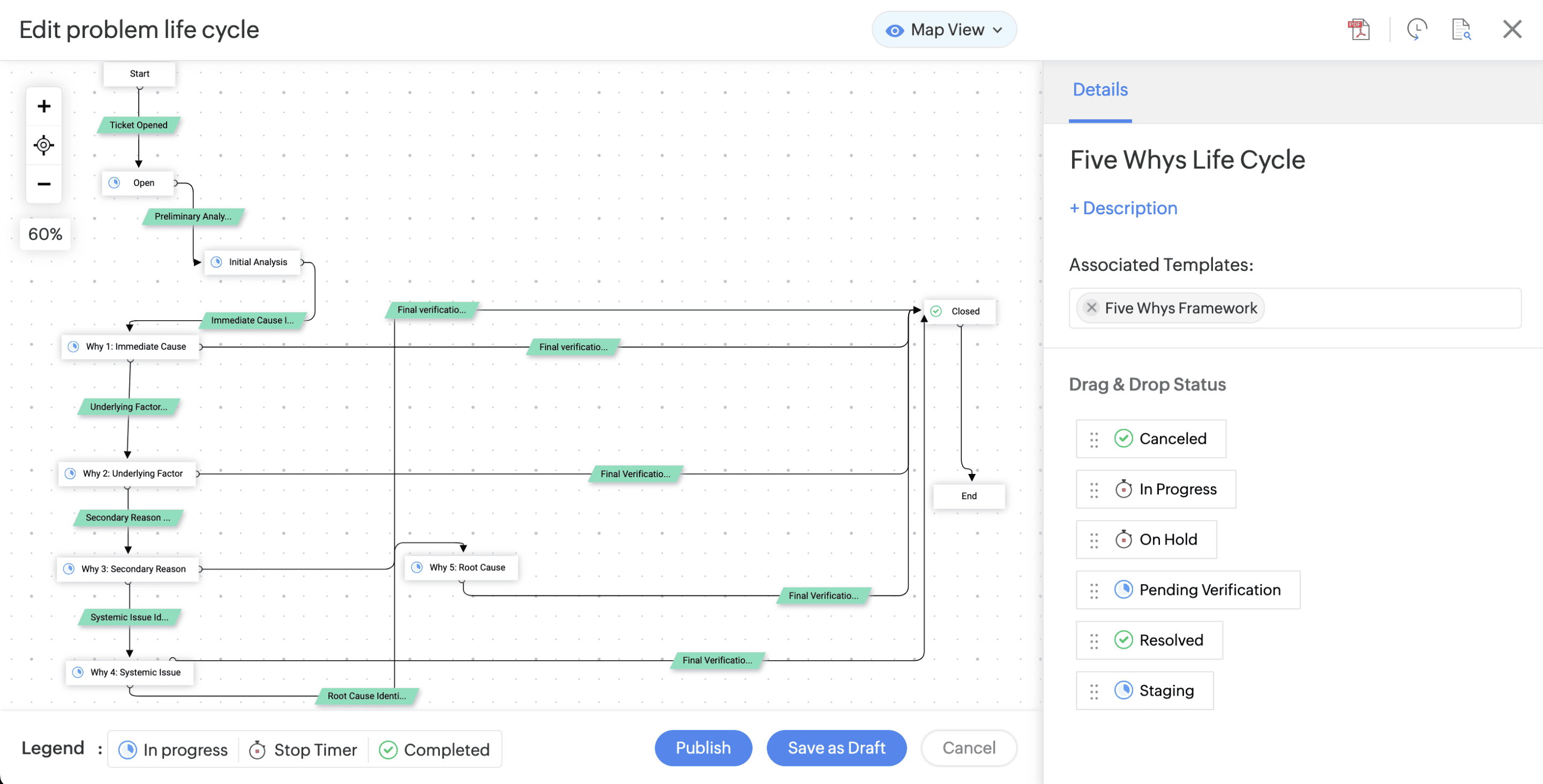
Teknik yang digunakan dalam proses problem management beragam, misalnya Five Whys, Kepner-Tregoe, Pareto analysis, dan Fishbone diagram. Untuk membuat proses problem management yang diterapkan di organisasi Anda selaras dengan teknik tersebut, Anda bisa membuat visualisasi workflow.
Itulah mengapa, fitur visualisasi workflow menjadi sangat penting dalam tool problem management. ManageEngine ServiceDesk Plus memiliki fitur visualisasi dengan kanvas drag-and-drop yang mudah digunakan, sehingga memungkinkan Anda untuk menstandarkan proses problem management dan menyesuaikannya dengan framework RCA yang populer. Selain itu, fitur ini juga bisa mengotomatisasi tugas berulang seperti memberi notifikasi kepada stakeholder tentang proses RCA, memperbarui field value, atau mengirim approval request.
4. Pencatatan masalah yang detail
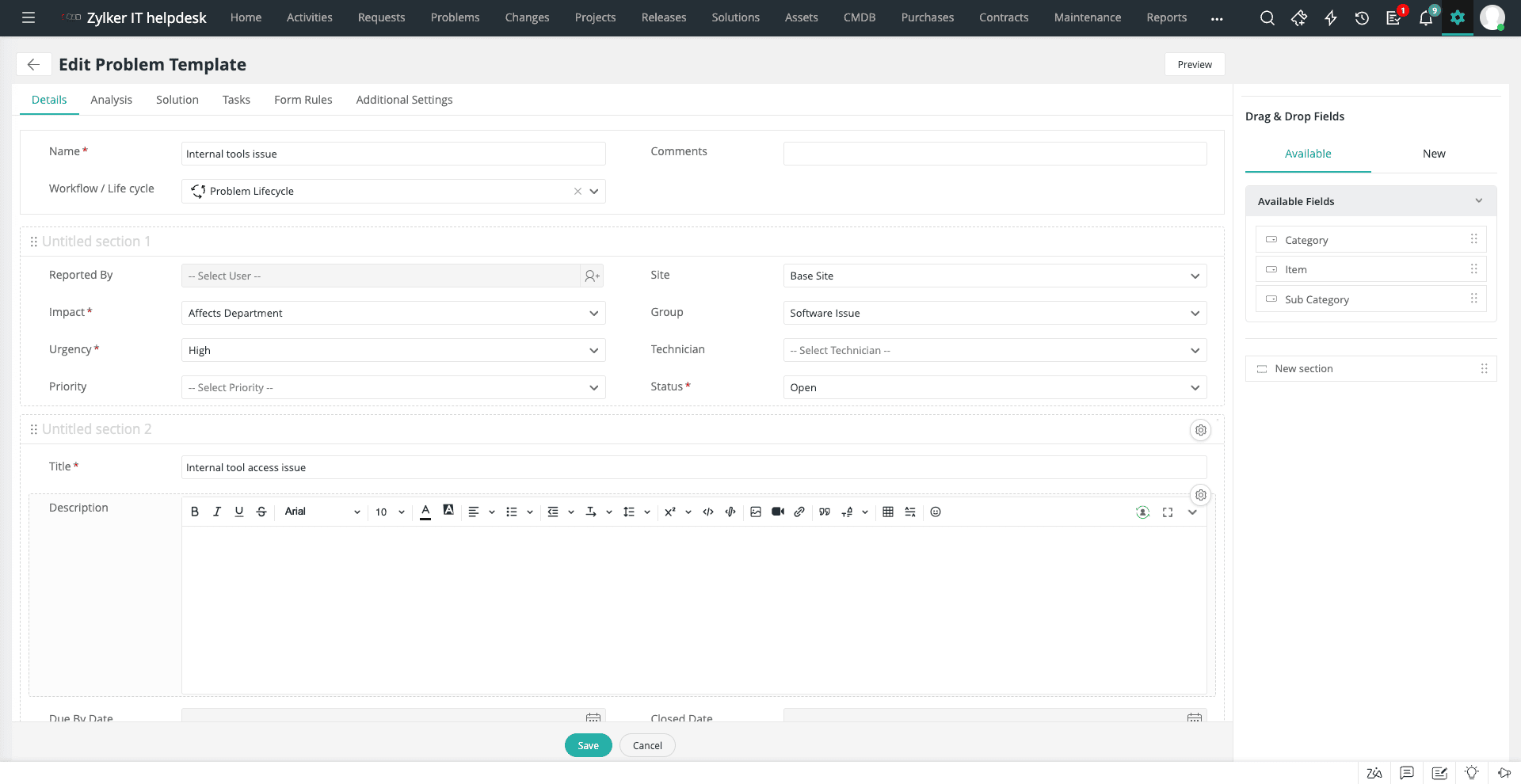
Sebuah software problem management yang baik seharusnya bisa mendokumentasikan setiap masalah dengan rinci, mulai dari gejala yang muncul hingga dampaknya terhadap layanan. Di ServiceDesk Plus, tersedia template yang dinamis dan dapat disesuaikan melalui kanvas drag-and-drop untuk mencatat setiap detail dari masalah.
5. Announcement
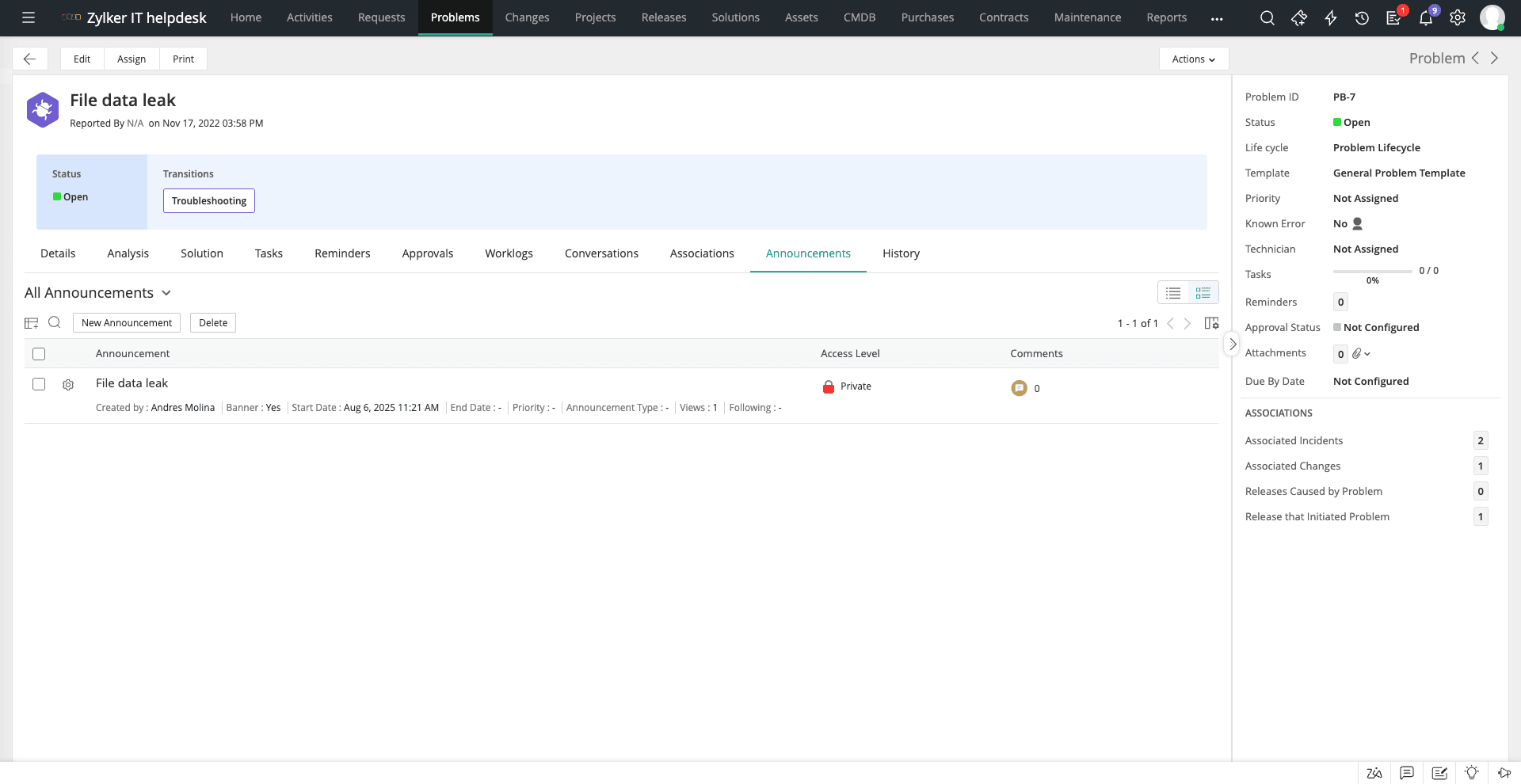
Problem management bukan hanya tanggung jawab tim ITSM atau problem manager saja. Perlu ada kolaborasi erat dengan stakeholder lain, termasuk tim service desk dan tim teknis. Dalam kolaborasi ini, komunikasi terbuka sangat penting. Salah satunya melalui fitur Announcement dalam tool problem management.
ServiceDesk Plus punya fitur tersebut. Dengan fitur Announcement untuk seluruh organisasi dan stakeholder, Anda bisa mengurangi duplikasi tiket insiden karena semua orang tahu masalah yang sedang diinvestigasi. Pengumuman yang dibuat pun bisa dilakukan di berbagai tahap problem management, mulai dari identifikasi, investigasi, hingga resolusi.
6. Repositori knowledge
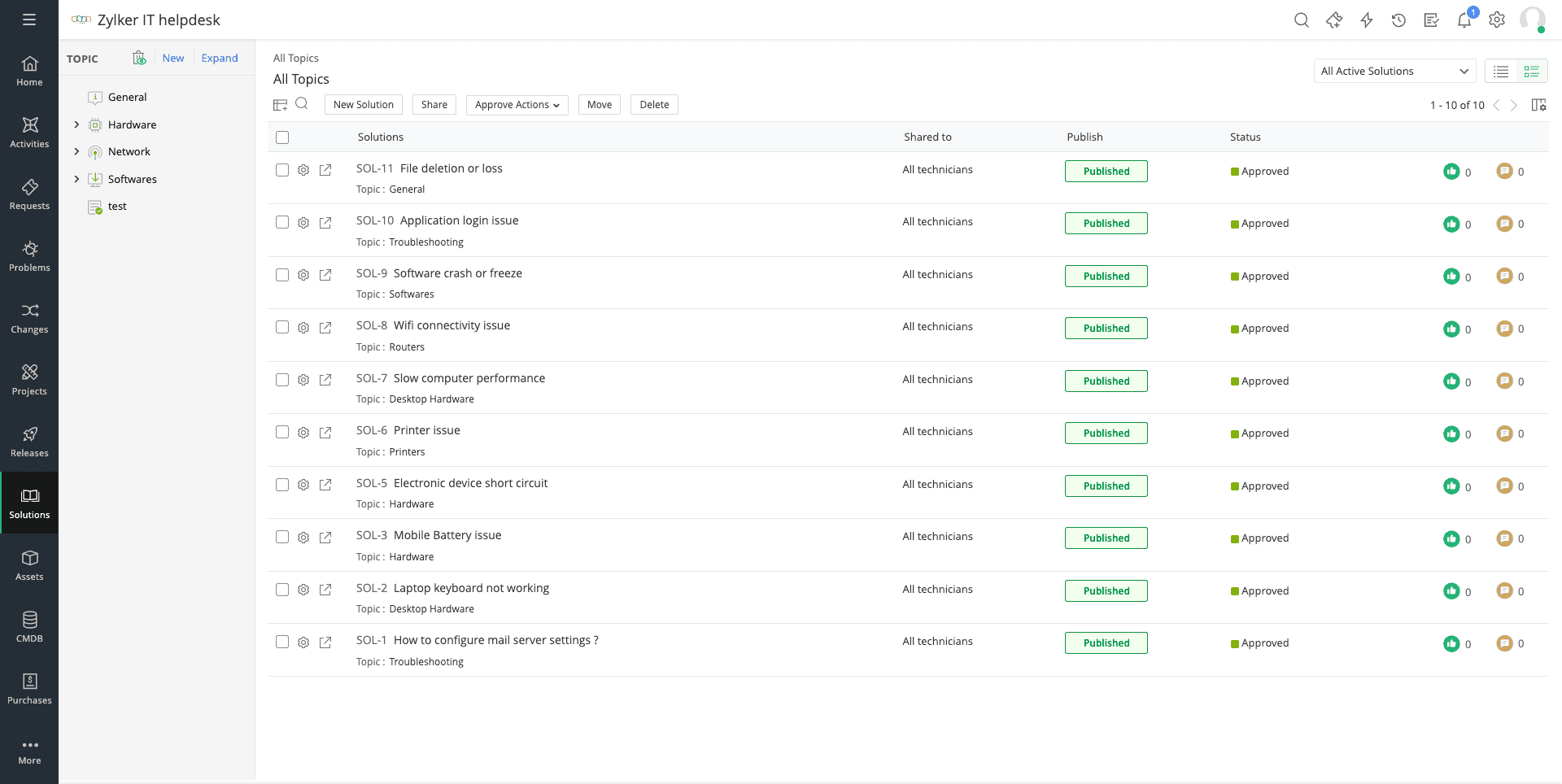
Repositori berguna untuk menyimpan semua dokumentasi terkait masalah, mulai dari gejala dan solusinya. Dengan repositori ini, tim bisa menjadikannya sebagai referensi ketika menghadapi masalah serupa di masa mendatang. Karena solusi sudah terdokumentasi, penanganan pun bisa lebih cepat dan pencegahan juga bisa dilakukan.
Jika ada masalah yang belum terselesaikan, tim bisa menandainya sebagai known error dan menyediakan workaround. Dengan begitu, pengguna tetap bisa melanjutkan aktivitasnya, sementara tim IT fokus mencari solusi permanen.
7. CMDB
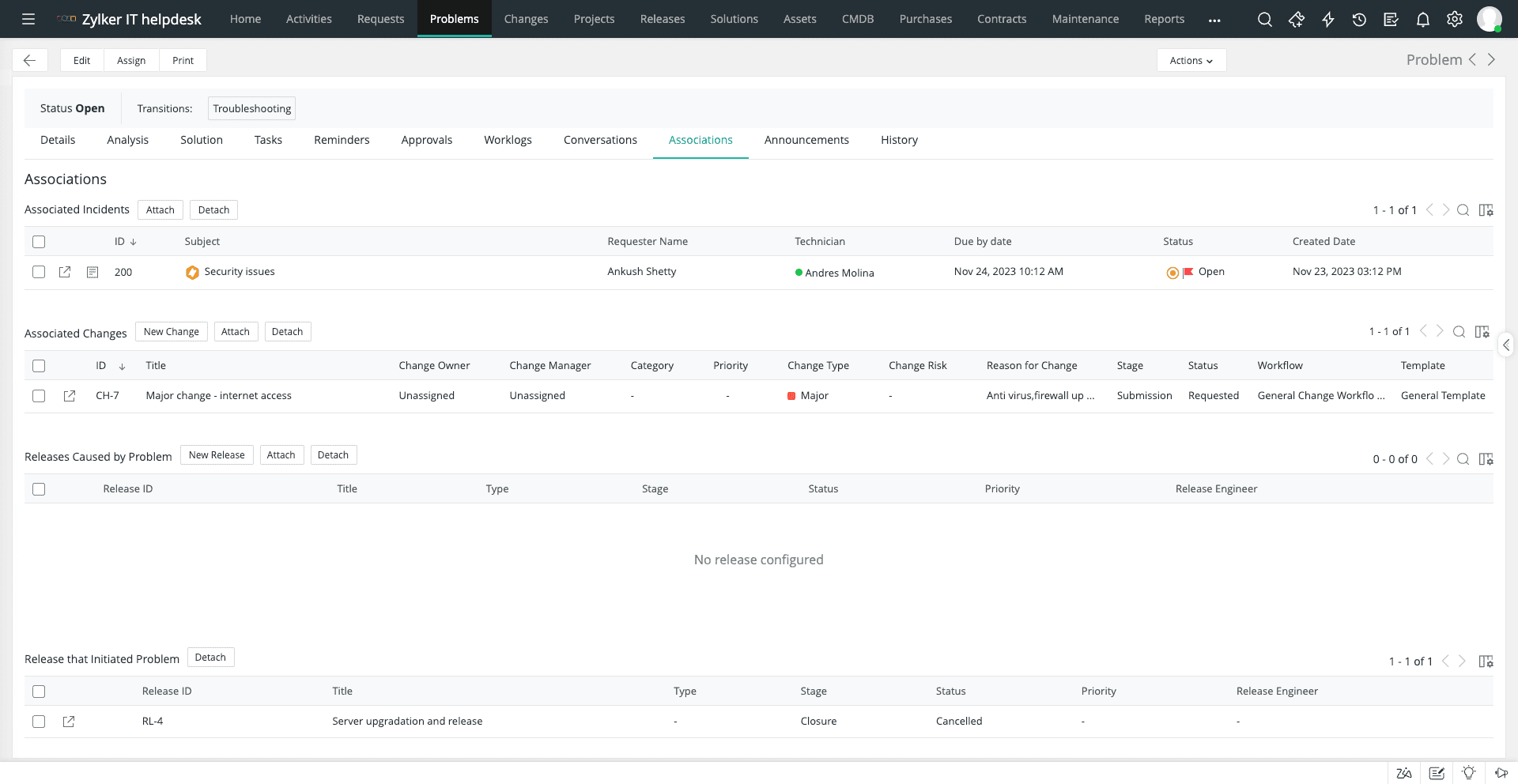
Problem management tidak berdiri sendiri, melainkan berkaitan erat dengan praktik ITIL lainnya seperti incident management, change management, dan release management. Di sinilah CMDB (Configuration Management Database) menjadi sangat penting.
Dengan fitur CMDB bawaan dari ManageEngine ServiceDesk Plus, tim bisa menganalisis dependensi dan dampak dari setiap masalah, serta menghubungkan configuration item (CI), insiden, perubahan, dan rilis langsung ke tiket masalah. Sehingga, tim bisa mendapatkan konteks masalah yang lebih lengkap dan mengatasinya dengan cepat.
Capai proactive problem management dengan ServiceDesk Plus
Dengan pendekatan proactive problem management, tim IT dapat mendeteksi akar masalah sebelum berdampak pada pengguna. Pendekatan ini tidak hanya menjaga stabilitas layanan, tetapi juga membantu organisasi menghemat waktu dan biaya yang biasanya habis untuk penanganan insiden berulang.
Untuk membantu menerapkan strategi ini secara efektif, ServiceDesk Plus dari ManageEngine hadir dengan fitur analitik, automasi, dan integrasi cerdas yang memudahkan tim IT mengidentifikasi pola gangguan dan mencegah insiden sejak dini. Mulailah langkah proaktif Anda hari ini dengan mencoba demo ServiceDesk Plus dan rasakan perbedaannya.