Melhore o monitoramento de rede com base em Inteligência Artificial

Monitorar redes é uma tarefa desafiadora porque elas continuam a evoluir para atender aos requisitos dos clientes em constante mudança. As empresas hoje dependem fortemente delas, e mesmo uma pequena interrupção pode levar a multas e perda de lucros.
É por isso que sua ferramenta de monitoramento também deve se transformar não apenas para ser dimensionada à medida que você cresce, mas também para oferecer novos recursos que atendam aos novos desafios impostos pelas crescentes demandas de uso colocadas em sua rede.
Vamos dar uma breve olhada nos recursos lançados recentemente no OpManager para mostrar como nossa solução evoluiu ao longo do tempo para atender aos requisitos dinâmicos do monitoramento de TI.
Se você já estiver usando o OpManager, recomendamos que você utilize esses recursos e aproveite para potencializar o seu monitoramento de redes.Análise de causa raiz do problema de monitoramento
Problemas de rede, como desempenho lento ou interrupção, são inevitáveis e comuns. Mas a chave está na rapidez em que ela volta à normalidade e em analisar a causa raiz do problema. O tempo médio de reparo (MTTR) é uma métrica importante que ajuda a medir o tempo real necessário para identificar, analisar e corrigir o problema.
Manter valores baixos de MTTR é importante para evitar violações de SLA e penalidades. Mas manter o controle sobre estes valores é mais fácil falar do que fazer.
As redes são sistemas complexos com centenas (se não milhares) de pessoas trabalhando nelas, e pequenos erros humanos, como configuração inadequada de dispositivos, podem interromper serviços importantes.Quando ocorre um tempo de inatividade ou um problema de desempenho é percebido, a primeira coisa que você precisa fazer é identificar a causa raiz o mais rápido possível e resolvê-la. Porém, a análise de causa raiz (RCA) geralmente leva mais tempo do que o necessário para resolver o problema.
Isso é exatamente o que o recurso RCA do OpManager ajuda a resolver. Ele permite que você visualize os dados de monitoramento de sua rede (incluindo seus dispositivos, interfaces e URLs) em uma exibição. Essa visibilidade centralizada permite que você analise, compare e correlacione problemas e reduza a causa raiz rapidamente.
Análise de caminho de rede
O roteamento é crucial para as redes e, quando há um problema, como o sequestro de rota, os pacotes que estão em trânsito podem cair no caminho e resultar em uma interrupção ou queda de desempenho. Isso pode levar à interrupção do serviço e deixar os clientes insatisfeitos.
A análise de caminho de rede no OpManager ajuda a o visualizar inteiramente entre a origem e o destino. Ele mostra o desempenho salto a salto dos vários caminhos em sua rede e permite que você identifique exatamente onde está o problema. Por exemplo, o problema pode estar no seu ISP ou em um roteador de conexão em sua LAN. Você também pode identificar problemas de forma proativa e rastrear por que ocorrem atrasos no trânsito. Ao configurar valores limite para métricas como perda de pacotes e latência, você pode ser notificado sempre que os níveis ideais forem violados.
Você também pode identificar problemas de forma proativa e rastrear por que ocorrem atrasos no trânsito. Ao configurar valores limite para métricas como perda de pacotes e latência, você pode ser notificado sempre que os níveis ideais forem violados.Threshold Adaptativo
Seguir uma abordagem proativa no monitoramento ajuda você de duas maneiras:
Evitar problemas em cascata em uma interrupção.
Reduzir o número de reclamações de usuários finais.
Se você já é um usuário, sabe como a opção de configuração de violação de limite ajuda a identificar problemas iminentes que podem prejudicar seriamente sua rede.
A configuração manual de limites para dispositivos críticos é boa, mas o uso de cada dispositivo varia com base nas demandas impostas a ele. Por exemplo, para determinados servidores de missão crítica, a utilização média da CPU será de 85 a 90%, enquanto para os não críticos, a utilização da CPU pode ser de cerca de 60%.
Se você definir o valor de limite comum para todos esses servidores em, digamos, 80%, receberá alertas constantes, mas principalmente para os servidores de missão crítica. No entanto, você sabe que a porcentagem de utilização ideal de servidores de missão crítica e não crítica difere, por isso é importante definir valores de limite com base no uso, porque isso o ajudará a identificar com mais precisão anormalidades, se houver.
O recurso Threshold Adaptativo no OpManager altera dinamicamente o valor dos limites com base nas tendências anteriores. Ele usa o poder do machine learning para estudar as tendências de uso de cada dispositivo (com base em vários monitores) e, em seguida, gera um valor de previsão altamente confiável.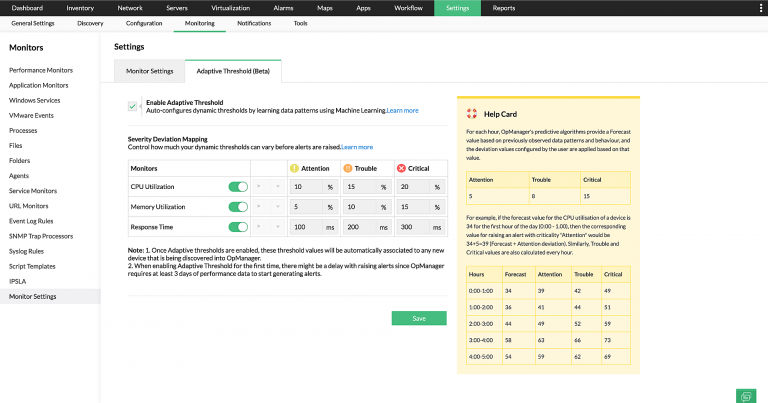
Como administrador de TI, seu trabalho será definir o valor do desvio, portanto, quando a utilização real cruzar o total da previsão e do valor do desvio, um alerta será gerado.
Previsão + valor de desvio = valor de threshold
Isso será muito útil na detecção de picos anormais fora do horário de trabalho. Com base nas tendências de uso anteriores, o OpManager aprenderá que o uso médio durante a semana é maior do que nos fins de semana e definirá os valores limite com base nesses dados históricos.
Por exemplo, durante a semana, o valor do limite para acionar um alerta de atenção será definido como 90%, portanto, quando a utilização da CPU atingir 85%, será considerado normal e nenhum alerta será gerado.
No entanto, para a mesma métrica, o valor do limite será definido como 60% durante os finais de semana, pois as CPUs são necessárias para executar apenas alguns serviços importantes. Portanto, se houver um aumento repentino no uso durante este período, um alerta será gerado para notificar sobre o problema.Recursos de aprimoramento de segurança
A segurança da rede é essencial para o crescimento dos negócios e qualquer violação pode ter efeitos duradouros e consequências graves, destruindo a reputação de uma empresa e resultando em uma enorme perda de receita.
Os dois recursos a seguir ajudam a exercer melhor controle sobre os privilégios de acesso do usuário com um mecanismo de autenticação mais forte.
Autenticação SHA-2 em SNMPv3
Desde o início do SNMPv1, houve melhorias constantes para aumentar a segurança, resultando nas versões evoluídas: SNMPv2 e depois SNMPv3.
O SNMPv3 foi considerado o melhor em termos de segurança por causa de seus recursos de autenticação e criptografia. Com a camada de autenticação, ele verifica se os pacotes de dados são recebidos de uma fonte válida e os criptografa para enviar para impedir que fontes não confiáveis leiam os dados.
No entanto, os algoritmos de autenticação — MD5 e SHA-1 — usados no SNMPv3 foram considerados vulneráveis ao longo do tempo.
Hash e segurança
SHA-1 retorna um valor de hash de 160 bits para a entrada fornecida. Geralmente, quanto maior o comprimento do valor retornado, melhor a segurança. Nesse contexto, seu sucessor, o SHA-2, que vem em duas versões – SHA-256 e SHA-512 – é capaz de retornar 256 e 512 bits de acordo com a versão utilizada e, portanto, oferece maior segurança.
O SHA-2 também pode produzir 2^256 e 2^512 valores de hash diferentes, evitando a colisão quando o mesmo valor de hash é repetido — um problema com o SHA-1, que gera 2^160 valores diferentes.
Além disso, desde 2017, grandes empresas de tecnologia como Microsoft, Google, Apple e Mozilla pararam de aceitar certificados SHA-1 SSL, pois foram considerados vulneráveis a ataques.
O OpManager foi pioneiro em estender o suporte ao algoritmo de autenticação SHA-2 para monitoramento baseado em SNMPv3 para permitir uma experiência de monitoramento segura.Autenticação SAML
O gerenciamento de usuários é um aspecto fundamental ao monitorar redes. Quando você não tem nenhum controle ou visibilidade sobre quem está acessando o quê em sua rede, isso pode criar uma maneira fácil para intrusos obterem acesso a dados confidenciais em sua rede.
O Security Assertion Markup Language (SAML) é um poderoso algoritmo de autenticação que ajuda a verificar a autenticidade de um usuário antes de permitir que o usuário faça login no OpManager.
Princípio de trabalho
Há dois componentes envolvidos na autenticação SAML: provedor de serviços (SP) e provedor de identidade (IdP). O SP é qualquer aplicação que fornece serviço a um usuário final; neste caso, é o OpManager.
O IdP é uma entidade que contém as credenciais do usuário, como nomes, senhas e chaves SSH.
Cada vez que um usuário faz login no OpManager (o SP), as credenciais do usuário são enviadas para o IdP, que por sua vez verifica a autenticidade e concede permissão para fazer login. Se o usuário for um intruso, o permissão é restrita.
Isso ajuda você a aumentar a segurança e rastrear tentativas de login maliciosas feitas em sua rede.Conclusão
O OpManager é uma ferramenta de monitoramento de rede rica em recursos que oferece todos os recursos mencionados acima, mas nossa equipe não para por aqui.
Acompanhamos ativamente o mercado, interagimos com os clientes, entendemos as suas necessidades e adaptamos os recursos de nossos produtos para atender a essas necessidades.
Dê uma olhada em tudo o que o OpManager pode te oferecer. Ou compartilhe suas ideias para um novo recurso para ser implantado no futuro!
Traduzido do artigo original: Enhance network monitoring with the latest AI-powered features in OpManager