Google Cloud Platform monitoring: Key factors to consider for advanced observability
As enterprises move mission-critical workloads to Google Cloud Platform (GCP), the need to monitor them closely all the time becomes even more crucial. GCP provides inherent elasticity, distributed service architectures, and on-demand provisioning—features that offer scalability but also introduce significant observability challenges. Because cloud environments are always changing, you need a smart monitoring plan to keep services running smoothly, control costs, and optimize performance.
In this blog, we will explore the essential factors to consider when selecting the perfect GCP monitoring solution for your company.
Defining GCP monitoring
Monitoring in Google Cloud involves collecting, analyzing, and displaying telemetry data like metrics, logs, and events from your infrastructure and services. It goes further than basic monitoring by using real-time analytics, anomaly detection, and auto-remediation capabilities. This helps teams respond to problems quickly and improve performance. The goal is to provide useful information so operations teams can find problems, predict failures, and constantly improve their workloads to meet business SLAs and SLOs.
Why GCP monitoring is essential
Even though Google Cloud has built-in tools like cloud monitoring and cloud logging, they often aren't enough for complex setups that use a mix of cloud providers or on-premise systems. Monitoring, therefore, evolves from a convenience to a necessity—particularly for organizations with complex application stacks and distributed microservices. Here's why:
Keeping critical applications always available: Organizations must ensure their most important services are always up and running.
Preventing slowdowns in auto-scaling services: They must also make sure that as services automatically expand or shrink, their performance doesn't suffer.
Meeting compliance and data rules: Keeping detailed records to satisfy regulations and data governance requirements is imperative.
Controlling costs: Organizations must analyze how resources are being used to manage and reduce spending.
Without a robust monitoring system, understanding what's happening in cloud-native environments becomes incredibly difficult. This means it takes longer to detect problems and longer to fix them when critical incidents occur.
Challenges in GCP monitoring
Despite advancements in observability tools, enterprises encounter persistent hurdles in monitoring GCP environments. Here are some of the main issues:
Complexity of hybrid infrastructure: Modern IT estates often span both on-premises and cloud infrastructure, with interdependencies across compute, network, and storage layers. It's hard to get a single, clear view of everything because these systems are all interconnected and different.
Difficulty managing cloud storage: Cloud storage services—ranging from object stores (e.g., cloud storage buckets) to database back ends—exhibit variable latency, performance degradation under concurrent access, and capacity sprawl. Monitoring solutions need to provide very detailed information on things like IOPS, data transfer rates, and data accuracy to prevent downstream impacts.
Finding the root cause in distributed systems: Traditional monitoring tools struggle with RCA in containerized, service-mesh-driven environments. To pinpoint where issues are coming from and understand why they happened, organizations need tools that can trace activity across different distributed services, map out dependencies, and link related alerts.
Tracking dynamic resources: Google Cloud's ability to scale resources automatically (like automatically growing or shrinking groups of instances or serverless functions) creates monitoring gaps if tools don't adapt to these constantly changing resources. Failure to capture ephemeral workloads can lead to blind spots.
Cost management: Telemetry ingestion and retention incur operational costs. Balancing the granularity of monitoring (e.g., one-second intervals versus five-minute rollups) with budget constraints is a perennial challenge, particularly in high-frequency data environments.
Integration with legacy systems: In hybrid IT environments, the seamless integration of GCP monitoring with legacy network monitoring tools (e.g., SNMP-based network management systems) and log aggregators is often inadequate. Connecting these different platforms requires strong APIs, connectors, and ways to make the data consistent.
Scalability: As businesses grow, their cloud environments also grow, making it challenging to scale monitoring processes and tools to keep up with increasing demands.
Core aspects of GCP monitoring
To truly understand how well your Google Cloud services are performing, you need a complete monitoring system that looks at every part of your cloud setup, not just basic infrastructure details. Here are the key areas to focus on when building or choosing a Google Cloud monitoring solution:
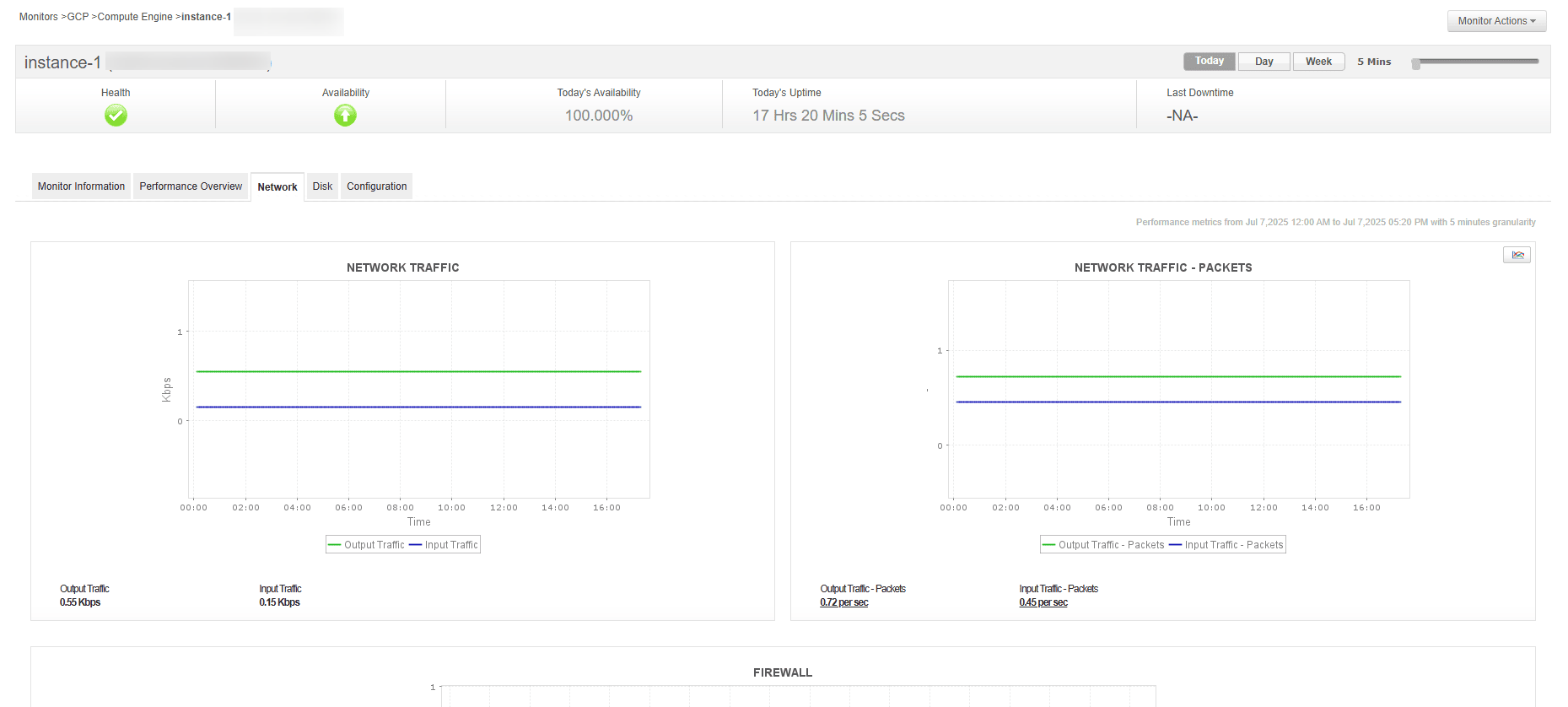
1. Compute monitoring
This involves effectively watching your computing resources, like Compute Engine virtual machines. A good monitoring solution should provide:
Real-time data on CPU usage, memory, disk activity (I/O), and what processes are running.
Smart detection of underused resources (e.g., virtual machines that are idle). This helps you save money by automatically shutting down or resizing these resources.
Application-level monitoring using agents to connect how much compute power your applications are using to their specific performance goals.
2. Storage telemetry
Google Cloud's storage services (like Cloud Storage and Cloud Filestore) need detailed monitoring to ensure they are available, fast, and free of errors. A strong monitoring solution should offer:
Analysis of read/write performance over time, showing trends and helping identify bottlenecks.
Dashboards for capacity planning to track how much storage you're using against your limits and spot any unusual usage patterns.
3. Container and orchestration insights
Since Kubernetes (GKE in Google Cloud) is so widely used for managing containers, monitoring containerized applications is crucial. Key capabilities in this area include:
Health metrics for individual nodes and pods (the smallest deployable units in Kubernetes).
Tracking events from the cluster autoscaler, which automatically adjusts the number of nodes in your cluster.
Alerts for resource conflicts, like when a CPU is being throttled or memory is being evicted (removed from a container).
Integration with service meshes (like Istio) to monitor communication between different services within your cluster (known as east-west traffic).
This container-focused monitoring should also support SLOs and the "golden signals" (latency, traffic, errors, and saturation) at both the individual microservice level and across entire namespaces (groups of resources within a cluster).
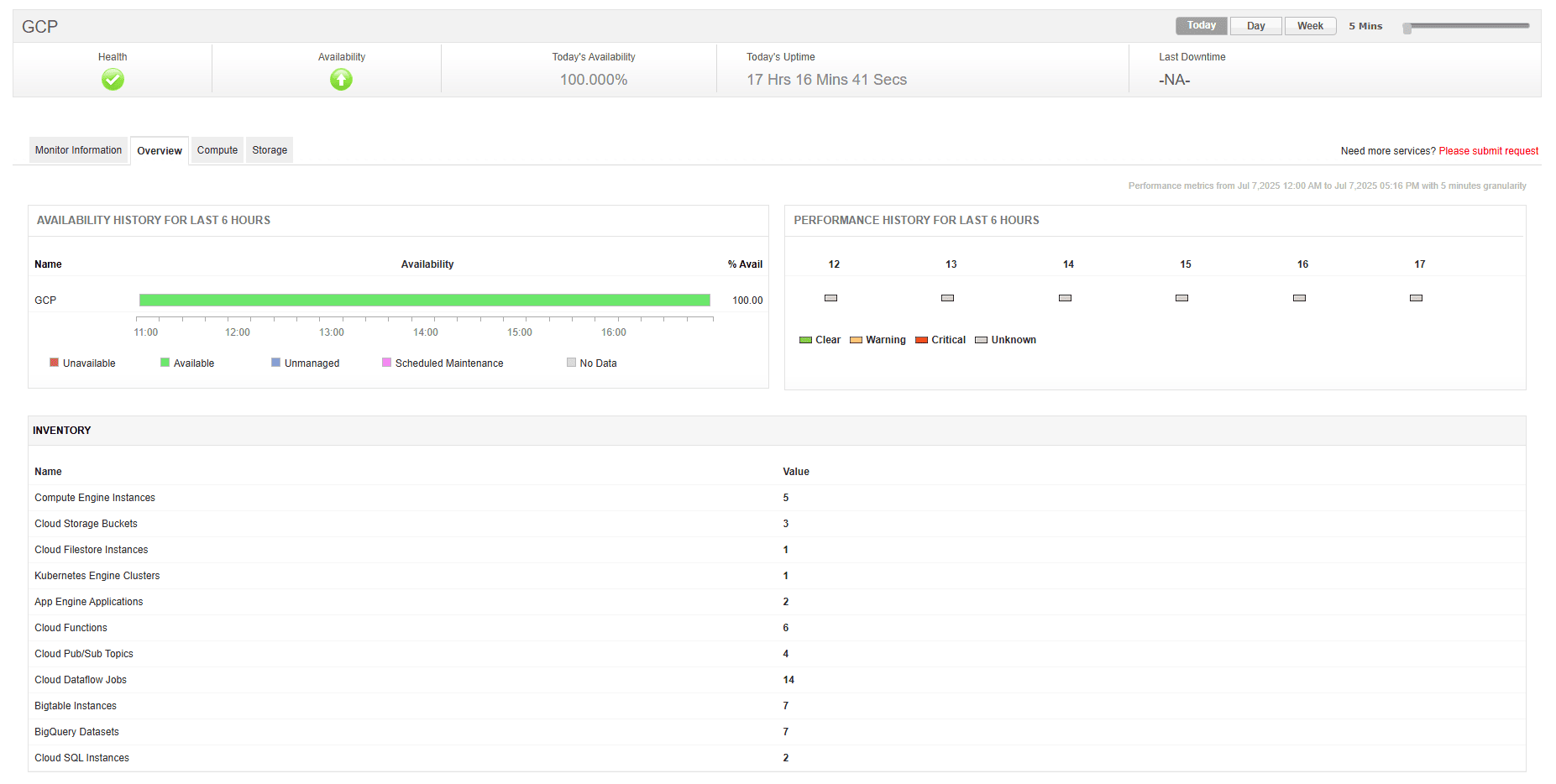
GCP monitoring with ManageEngine Applications Manager
ManageEngine Applications Manager offers a comprehensive suite for GCP monitoring. It's designed to monitor various layers of your cloud services, including compute resources, storage services like cloud storage, and container services (GKE).
Key capabilities include:
Real-time performance tracking across GCP-native services.
Advanced alerting mechanisms with escalation policies and integrations (e.g., Slack and ServiceNow).
Reporting and trend analysis tools for long-term optimization.
Support for hybrid environments, unifying visibility across on-premises and cloud assets.
Beyond basic monitoring, Applications Manager enhances its capabilities with AI-powered anomaly detection and customizable dashboards.
If you are yet to discover the benefits of Applications Manager, now is the perfect time to do so. With a free, 30-day trial, you can effectively monitor your Google Cloud infrastructure resources and workloads, in addition to other vital components, without delay.