
Kafka is a distributed streaming platform that acts as a publish-subscribe messaging queue by receiving data from various source systems and making it available to various systems and applications in real time. Key advantages for utilizing Kafka are that it provides durable storage, meaning the data stored within it cannot be easily tampered with, and it is highly scalable, so it can handle a large increase in users, workloads, and transactions when necessary.
Because Kafka can handle large volumes of data, many organizations that deal with big data and events, such as Netflix and Microsoft, use Kafka. To ensure optimal performance of the Kafka middleware server, and seamless operations of various business-critical applications that rely on it, it is crucial to utilize a monitoring solution.
ManageEngine Applications Manager provides proactive Kafka monitoring and helps you identify and resolve issues quickly, before they impact your applications. Kafka reports crucial metrics that directly relate to the performance of your Kafka server. Let us take a look at the key Kafka performance metrics you need to monitor to manage your Kafka servers efficiently.
Memory usage
Kafka, unlike other middleware technologies, runs entirely on RAM. Because the user analytics tool heap requires a large pool of memory in the RAM, heap memory is allocated dynamically depending on the number of incoming requests to the server. In a Kafka instance, it is crucial to always ensure that the Java virtual machine (JVM) heap size isn’t bigger than your available RAM to avoid swapping.
Applications Manager’s Kafka monitoring tool allows you to monitor memory metrics such as physical memory, virtual memory usage, and swap space usage. Keeping track of swap usage helps avoid latency and prevents operations from timing out.
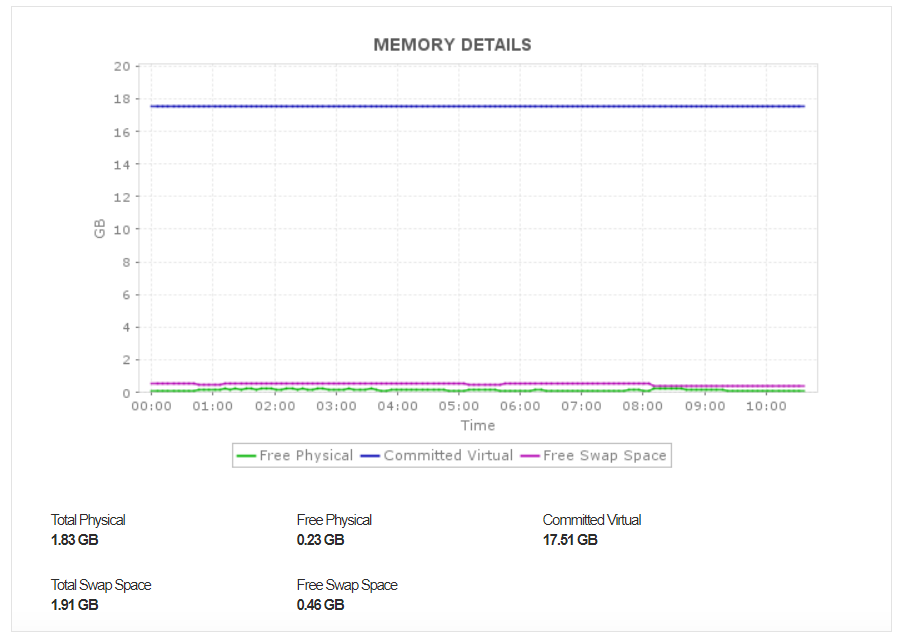
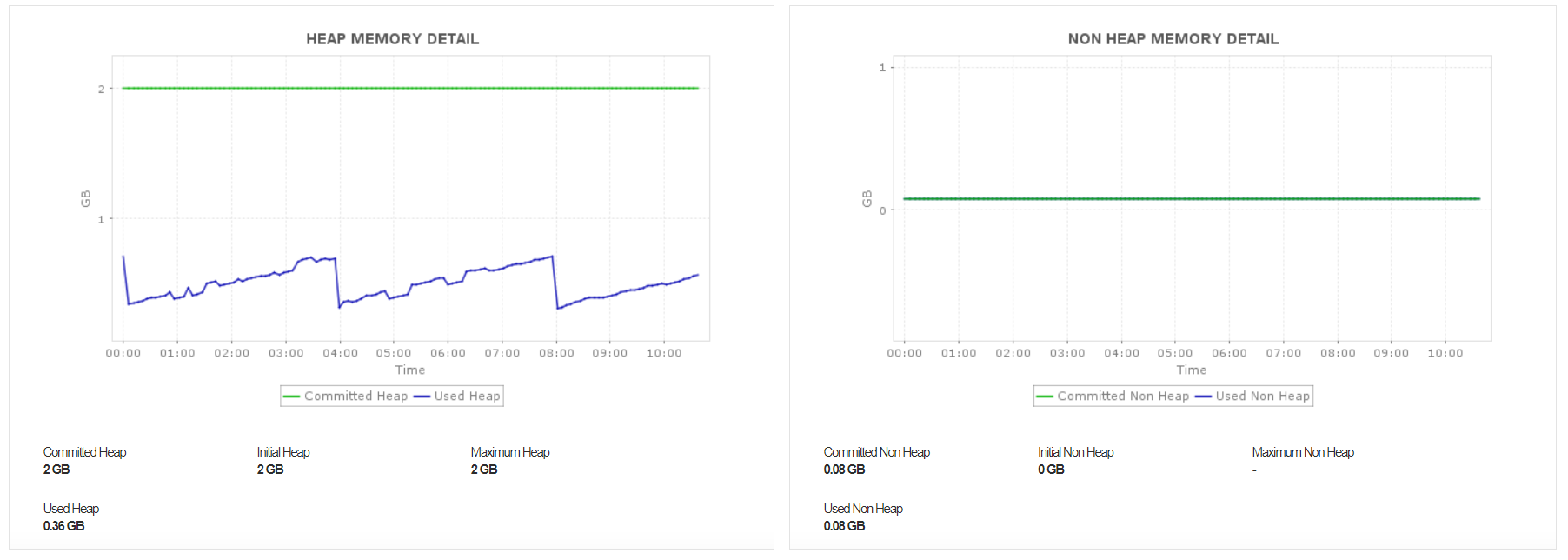
The Kafka JVM has two segments: heap memory and non-heap memory. While the heap memory stores the actual data objects, the non-heap memory keeps track of the metadata and loaded objects. Applications Manager’s Kafka monitor keeps track of your heap usage to help you detect memory leaks with ease.
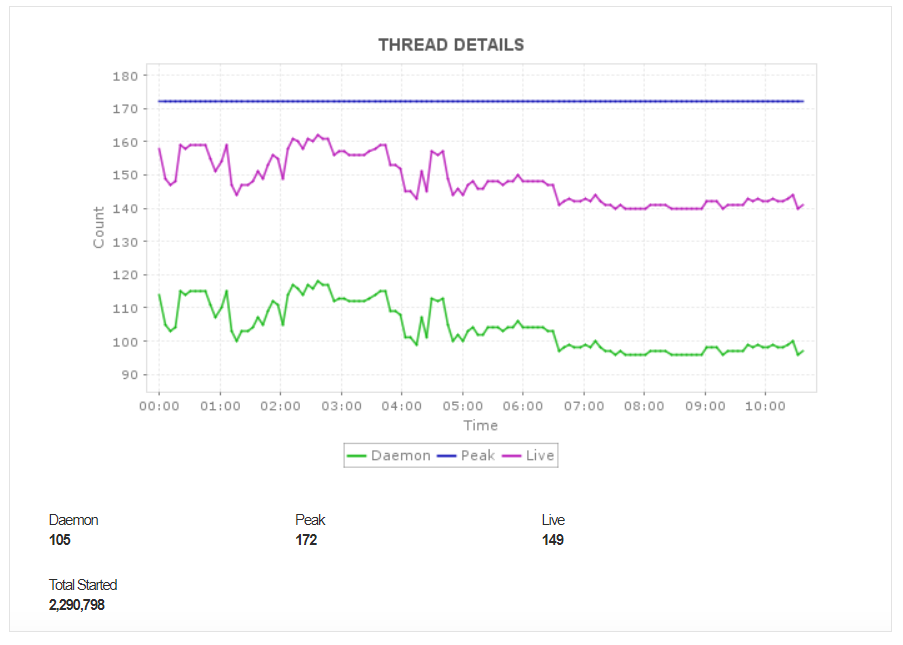
Thread details
All requests in a server are handled by processes that are broken down into several threads that execute simultaneously to help take care of incoming requests faster. This helps reduce response time and improves the responsiveness of the server.
Applications Manager’s Kafka server monitoring capabilities enables you to track the threads in the JVM in your Kafka instance and provide details about various threads:
-
Daemon Threads: These are threads that do not prevent the JVM from exiting when the program finishes while they still run in the background.
-
Live Threads: These are the threads that are currently active.
-
Peak Threads: This is the maximum number of threads executed in the JVM.
Monitoring threads in the JVM can prove to be useful in many ways. If there is a sudden spike in the CPU usage, you can analyze thread details to identify which thread is causing it. Monitoring the number of live threads primarily helps you to identify if the current usage of any pool is close to its maximum. You can identify idle threads and remove them, thereby preventing requests from being rejected.
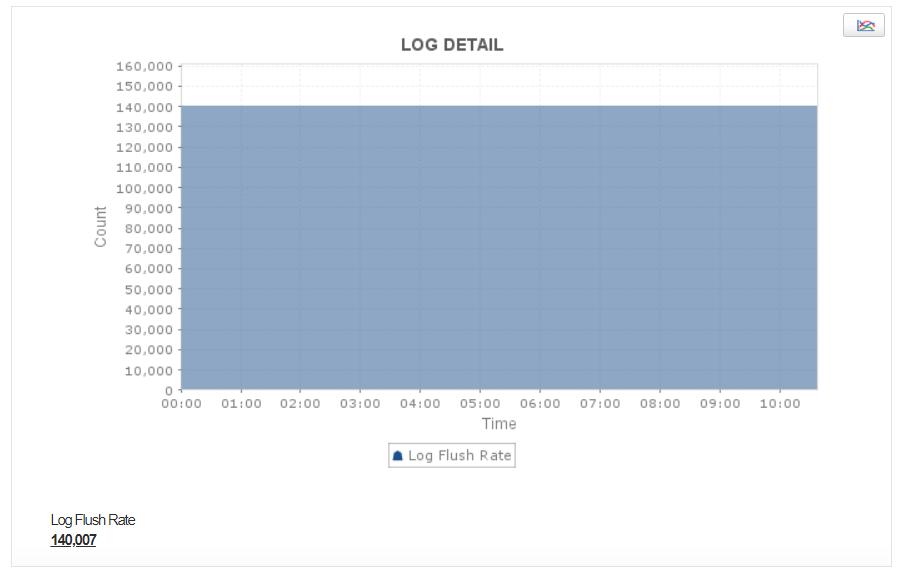
Log Flush Rate
Records in Kafka are published in a stream of records called topics. Each topic has a designated partitioned log that request details are appended to whenever data has to be stored. Each partition is a structured commit log that has a sequence of records that are labeled and assigned a sequential ID for identification purposes.
These records are written to the disk after a specific period, after which they are flushed off the partitions. The flush rate, the time it takes to flush the log to the disk, is an important metric to monitor, and is a direct indicator of your Kafka instance’s performance.
Applications Manager monitors the Log Flush Rate and notifies you if the value crosses a set threshold. A high value of log flush rate may cause requests to be held in the queue, resulting in latency and performance degradation of your Kafka middleware server. This is an indication that you might have to check your hardware for bottlenecks, or scale your server accordingly.
Broker topic metrics
An efficient server always handles requests quickly, without any latency. Monitoring broker topic metrics can give visibility into the overall performance of your Kafka server.
Applications Manager monitors various Kafka monitoring metrics including broker topic metrics to help you understand message throughput and fluctuations. Monitoring the Bytes In/Min helps identify large messages, while Messages In/Min serves an indicator of the load on the server. Monitoring Failed Fetch Requests/Min and Failed Produce Requests/Min can help detect performance degradation in your server.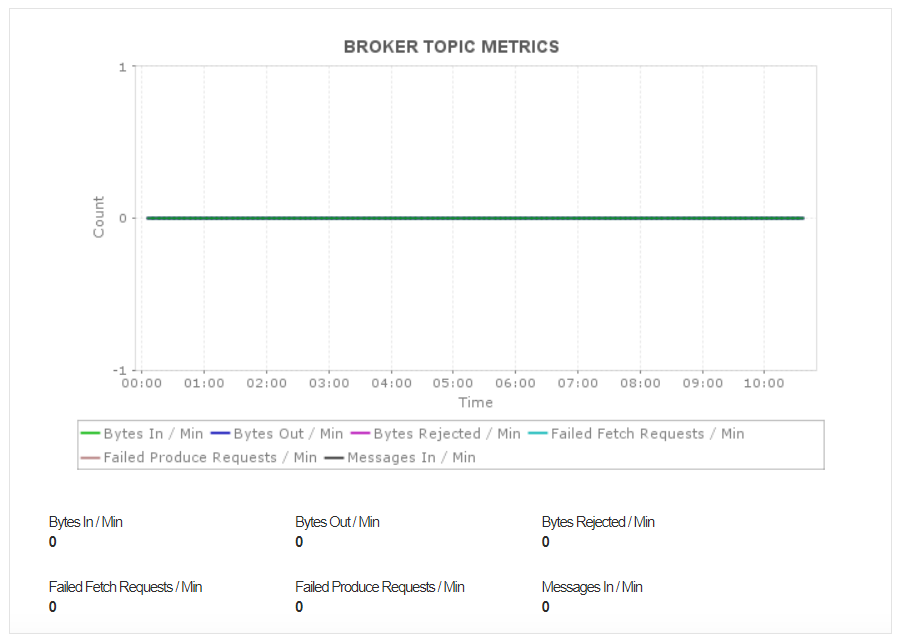
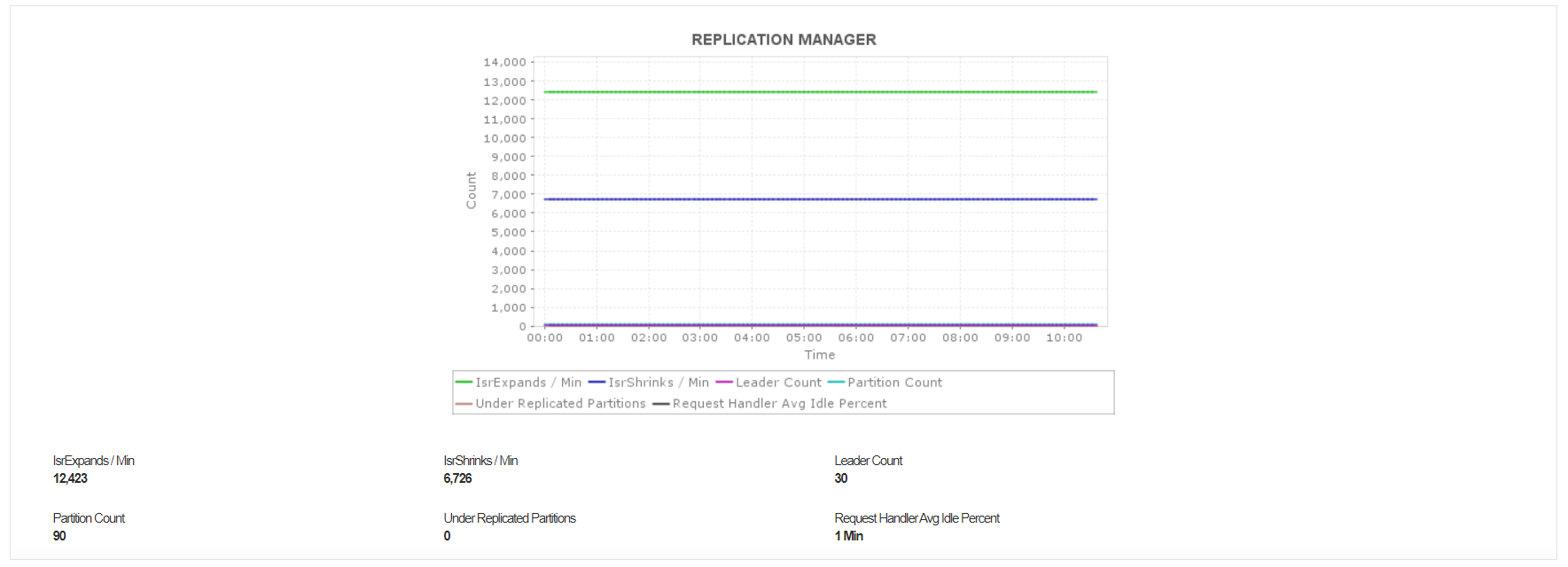
Replication
Replication in Kafka involves creating copies of the data to ensure its availability in the event of a broker becoming unavailable. This can cause performance degradation as the broker will not be able to service any requests if it becomes unavailable, thereby increasing the Under Replicated Partitions count.
A huge challenge with replication in Kafka involves maintaining the In Sync Replica Count in congruence with the Total Replica count. Replicas that are not in sync are the partitions that fall behind the leader, and are removed from the in-sync replica (ISR) pool, thereby increasing the value of IsrShrinks/Min.
Applications Manager keeps an eye on critical Apache Kafka monitoring metrics such as IsrShrinks/Min and IsrExapsnds/Min, Under Replicated Partitions, and also notifies you of threshold violations to ensure optimal performance of your Kafka middleware server.
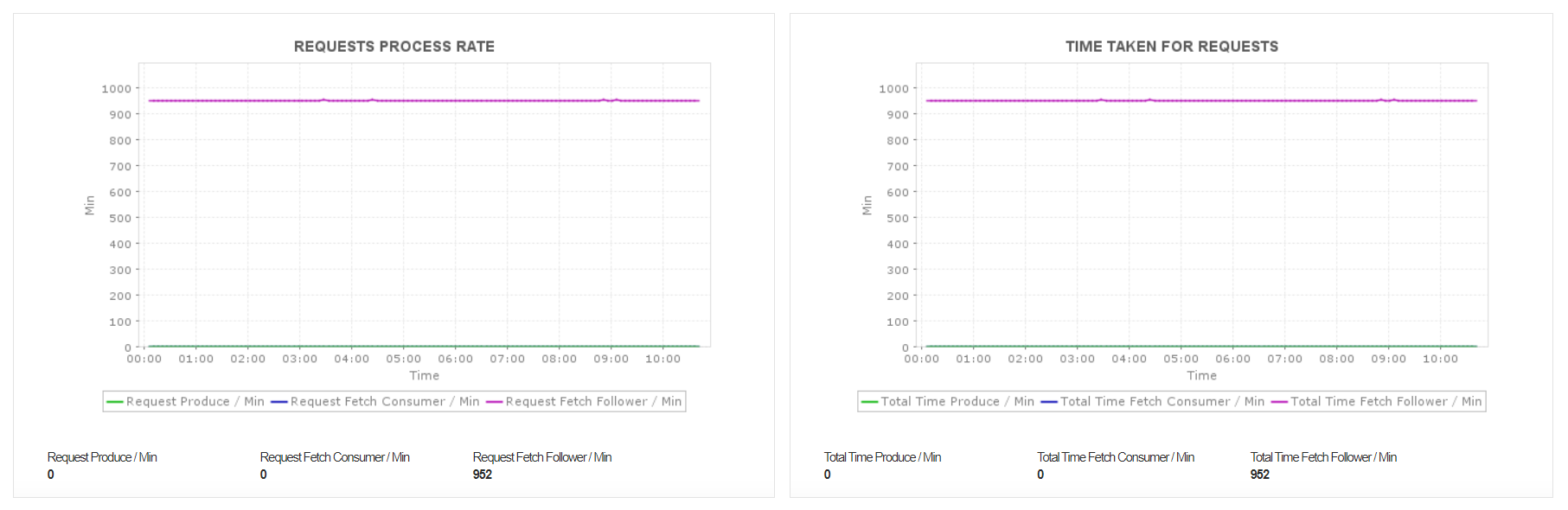
Network details
Kafka handles a large number of events. It is imperative to monitor the requests occurring per second to gain visibility into the network throughput and the load on the server.
Applications Manager monitors the Request Process Rate and notifies you of spikes. This can help you analyze which broker’s bandwidth has been affected so that you can increase the number of brokers utilized when necessary. It also helps you to detect latency in the server.
Controller details
In a Kafka cluster, one of the brokers acts as a controller, and is responsible for maintaining the states of partitions and replicas. When a partition leader dies, an election for a new leader is triggered. Any available in-sync replicas for the partition are eligible to become the new leader. Leader elections cause a small delay in responding to requests to that partition while the new leader is being chosen. Keep an eye on the Leader Election Rate metric to know the rate of leader elections.
Unclean leader elections are caused by the inability to find a qualified partition leader among Kafka brokers. When a broker that is the leader for a partition goes offline, a new leader is elected from the set of ISRs for the partition. An unclean leader election is a special case in which no available replicas are in sync. Applications Manager allows you to keep track of the number of unclean leader elections per second and understand if there was any data loss.
The metric Offline Partitions Count helps you keep track of the number of partitions that are not writable or readable since they do not have an active leader.You can configure settings so you can be alerted if this value goes above 0, since a partition without an active leader will be absolutely unreachable. That would mean both consumers and producers of that partition will be blocked, causing unnecessary delays in processing requests in the server, until a leader becomes available.
Monitor ZooKeeper metrics along with Kafka
ZooKeeper stores metadata about Kafka’s brokers, topics, partitions, and system coordination. An outage or slowness of ZooKeeper can affect Kafka clusters. You should also monitor ZooKeeper metrics to maintain a healthy Kafka cluster.
If you are just getting started with Kafka monitoring, these are a few of the metrics that show how monitoring your Kafka instance can help you achieve better application performance. To learn how Applications Manager can improve your Kafka monitoring capabilities even further, download a 30-day free trial right away!