Modelo de dados relacional: tudo o que você precisa saber

Dados podem ser um tema sensível para alguns, especialmente porque, quando em grandes quantidades, podem deixar algumas pessoas desnorteadas.
Agora, imagine que você tenha dados registrados em lugares distintos e que precise conectá-los para uma tarefa específica. Para quem faz isso, essa função pode se tornar exponencialmente mais difícil.
E é basicamente isso que o modelo de dados relacional trata: relacionar dados de dois lugares diferentes. Mas quer entender melhor sobre esse assunto? Fique tranquilo que vamos destrinchar esse assunto para você ficar confortável com os dados, independente de seus tamanhos, quantidades e locais.
Tipos de modelos de dados
Antes de começar a falar sobre o modelo de dados relacional, precisamos mencionar que há outros tipos e cada um tem um objetivo específico, já que existem diferentes tipos de bancos de dados.
Modelo de dados hierárquico
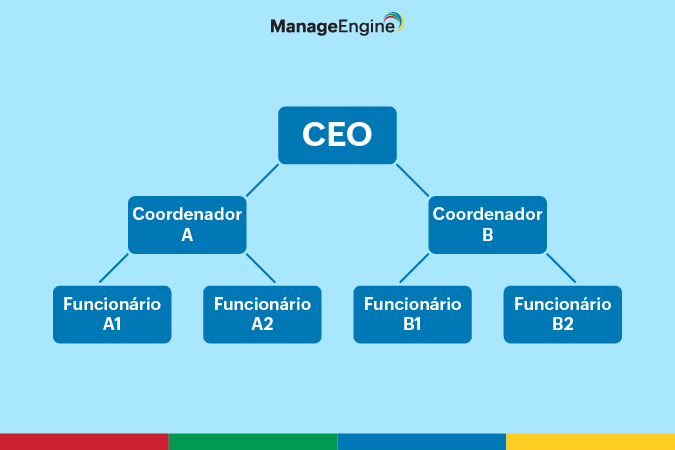
Este se caracteriza por ter uma estrutura semelhante a uma árvore e um relacionamento pai-filho, ou seja, os dados (pais) podem ter diversas ramificações (filhos). É importante dizer que cada filho só pode ter um pai, porém um pai pode ter diversos filhos.
Por conta disso, esse tipo de modelo também é separado em níveis, já que por conta de serem bem delimitados, os níveis são facilmente visíveis.
Esse modelo é muito utilizado ao tratar da hierarquia de uma empresa.
Modelo de dados de rede
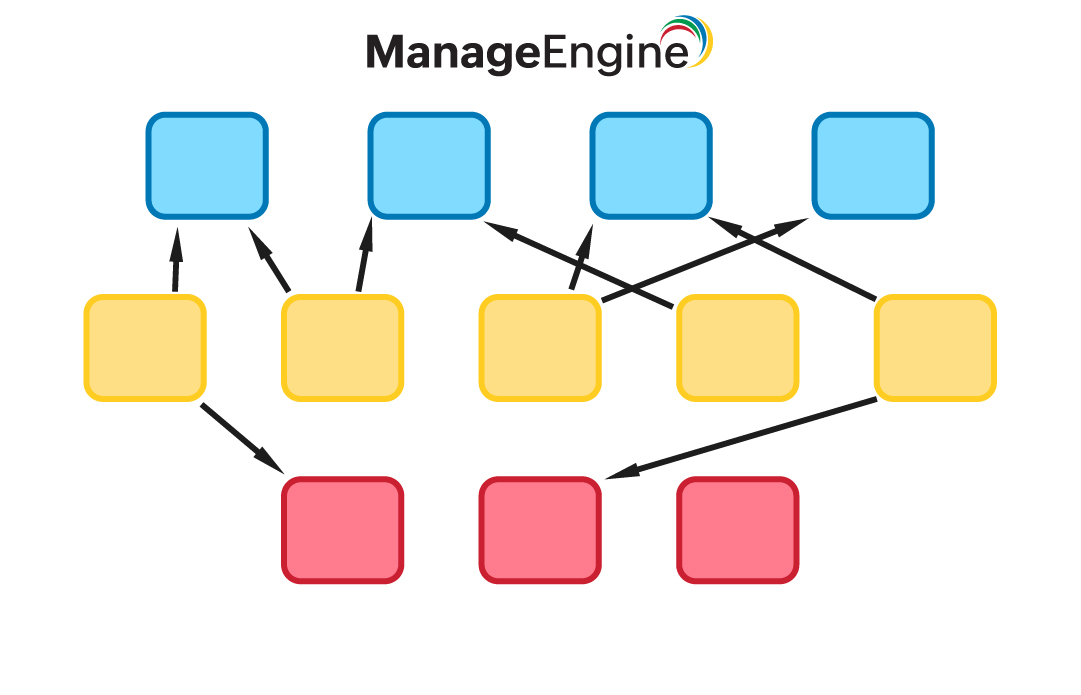
É caracterizado por ser semelhante a uma rede com diversas conexões entre cada um dos dados presentes.
Cada dado, ou "nó", pode ter diversas ligações com outros nós, semelhante ao modelo hierárquico, entretanto, nesse modelo, ou seja, cada filho pode ter mais de um pai, assim como cada pai pode ter mais de um filho.
Modelo de dados orientado por objetos (ODM)
Neste modelo, podemos agrupar diversos dados para simbolizar um objeto, ou seja, diferentemente dos anteriores, em que cada dado representava uma informação singular, este caracteriza um objeto como um conjunto de dados.
Esse tipo é bastante utilizado em empresas que trabalham com big data ou então na modelagem de dados e aplicações mais complexos.
Modelo de dados não relacional ou NoSQL
Este daqui é o que mais se diferencia dos outros tipos. Isso porque aqui os dados não são representados em tabelas tradicionais, e podem ser classificados em vários tipos: documento, chave-valor, colunar e grafo.
Além disso, os dados não são representados como "pais" e "filhos" e sim como pares "chave-valor".
Esse modelo é muito mais flexível e escalável, pois permite armazenar dados em formatos como JSON ou XML. Além disso, ele trabalha com grandes volumes de dados distribuídos, lidando com as limitações dos bancos de dados relacionais em cenários modernos, como big data, alta escalabilidade e dados semi-estruturados.
Por serem dados não estruturados ou então semiestruturados, esse tipo é comumente utilizado em imagens, vídeos e mídias sociais.
Modelo de dados relacional ou SQL
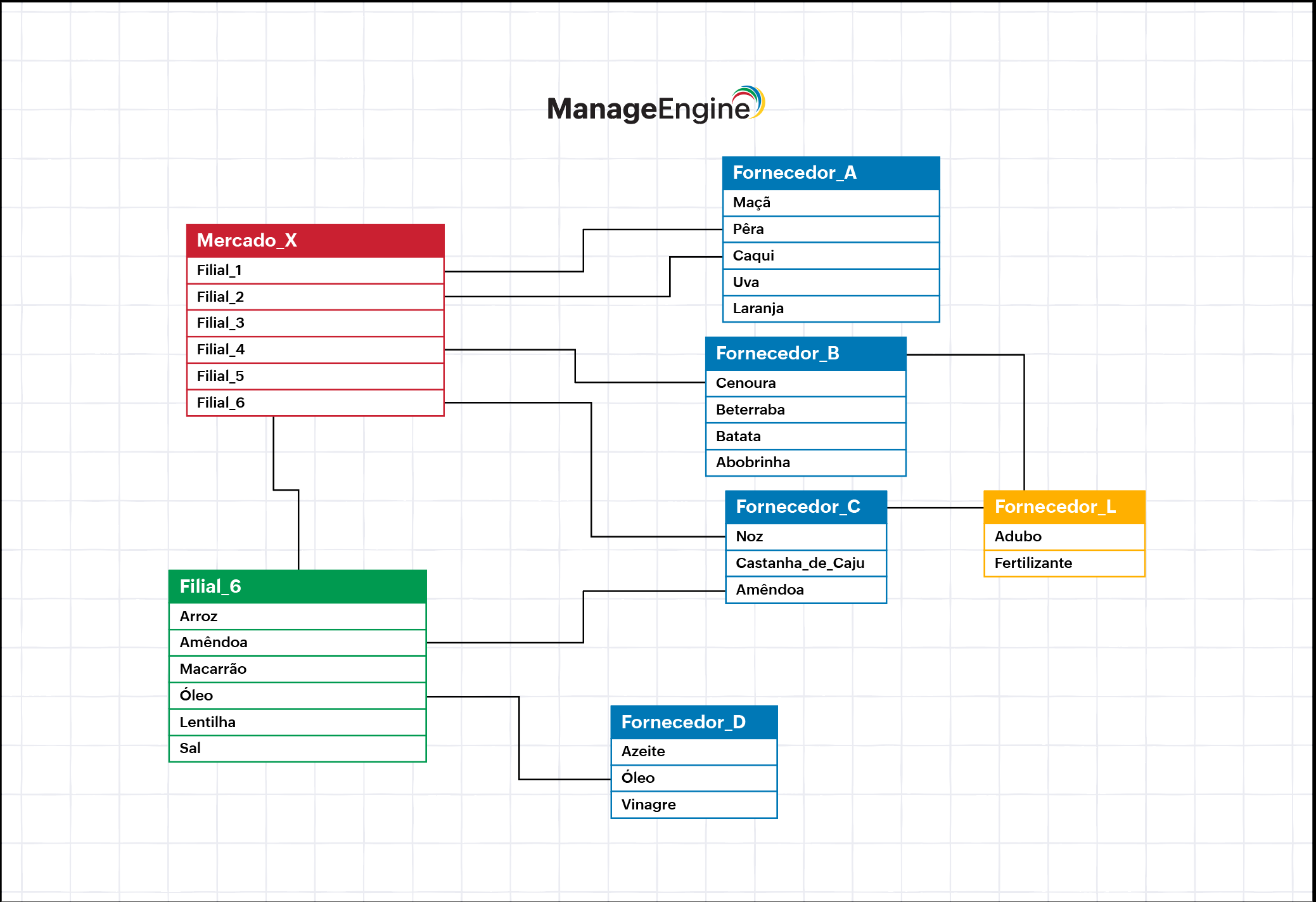
Esse tipo caracteriza-se por fazer uso de tabelas distintas que se conectam por terem dados relevantes e de interesse mútuo.
Ele é comumente utilizado para gerenciar dados estruturados, como em aplicações de CRM (Sistemas de Gerenciamento de Clientes), ERP (Sistemas de Gestão de Recursos Empresariais) ou mesmo CMS (Sistemas de Gerenciamento de Conteúdo).
Para saber profundamente sobre este modelo, leia o próximo tópico.
O que é um modelo de dados relacional
Como dissemos anteriormente, ele é composto por tabelas bidimensionais, ou seja, composto por tuplas e atributos.
Os dados são organizados em tabelas compostas por linhas (ou registros) e colunas (ou atributos). Cada tabela pode estar relacionada com outras por meio de chaves primárias (identificadores únicos para cada registro) e chaves estrangeiras (referências a outras tabelas).
Cada tupla e atributo armazena um tipo diferente de informação, geralmente os atributos contendo um mesmo tipo de informação; e as tuplas contendo diferentes informações sobre um mesmo objeto.
Esse tipo, como dissemos anteriormente, é comumente utilizado para armazenar dados pessoais, como: nome, CPF, endereço, número de telefone, entre outros.
Componentes do modelo de dados relacional
Tabela ou Entidades
Essa é a estrutura básica, ou seja, a primeira coisa que vemos ao observar um modelo desse tipo. É nela em que iremos armazenar todos os dados necessários.
É comum que haja mais de uma tabela em um modelo de dados relacional.
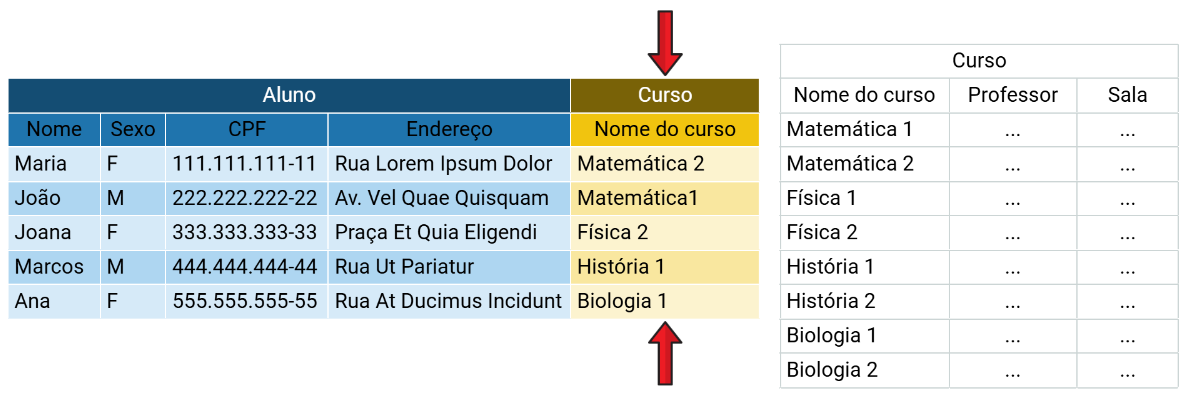
Tuplas, Linhas ou Registro
As tuplas podem ser distinguidas por serem as linhas horizontais de uma tabela. Cada linha geralmente representa diferentes informações sobre um mesmo objeto.
Cada uma delas deve ser identificada por uma chave primária, de modo que não haja a duplicação dos valores/dados presentes.
Atributos ou Colunas
Elas representam toda a parte de linhas verticais de uma tabela. Cada coluna representa um mesmo tipo de informação, porém sobre diferentes objetos.
Diferentemente das tuplas, aqui os valores podem se repetir em outras linhas da mesma tabela.
Relacionamentos
É a ligação que duas tabelas ou entidades tem. Esse vínculo geralmente se dá através das chaves primárias e chaves estrangeiras.
Chaves
Existem dois tipos de chaves, e cada uma delas tem uma função específica dentro do modelo de dados relacional.
Primária (PK - Primary Key)
Ela identifica exclusivamente cada registro, ou seja, é uma informação que não se repete em uma tabela de banco de dados. Além disso, é recomendável que cada tabela tenha uma chave primária.

Estrangeira (FK - Foreign Key)
É o campo para o qual a chave primária faz relação, seja da mesma tabela ou de outra. O valor da chave estrangeira pode se repetir diversas vezes entre os dados.
Composta
É a junção de dois ou mais campos dentro da tabela. Dessa maneira, o conjunto desses diferentes campos tornam a chave composta única, tornando-a uma espécie de chave primária.
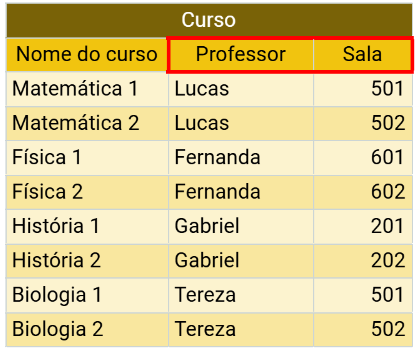
Tipos de relacionamentos
Como vimos, existem diversos tipos de dados e chaves dentro do modelo de dados relacional. Por esse motivo, é comum que haja diferentes tipos de relacionamento entre eles.
A seguir citaremos os três tipos existentes dentro do MDR.
1:1 ou um para um
Cada registro da primeira tabela pode ter somente um registro correspondente na segunda tabela, e consequentemente, cada registro na segunda tabela só pode ter um registro correspondente na primeira tabela.
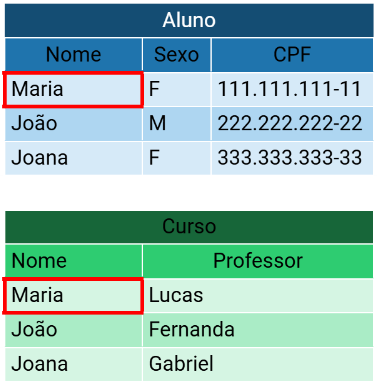
1:n ou um para muitos
Aqui um registro da primeira tabela pode ter muitos registros correspondentes na segunda tabela.
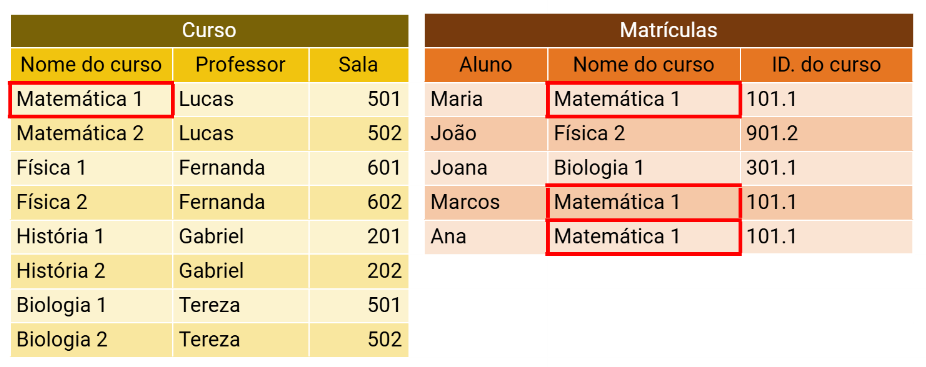
n:n ou muitos para muitos
Neste, cada registro da tabela A pode ter muitos correspondentes em outras tabelas, como na tabela B, ao mesmo tempo que cada registro da tabela B pode ter vários correspondentes na tabela A.
SGBD - Sistemas Gerenciadores de Banco de Dados
Um tipo de software que é utilizado para gerenciar a estrutura e as informações dos bancos de dados. Eles precisam ter uma capacidade alta de processamento para permitir a gestão do banco de dados e também uma capacidade de armazenamento que dê conta do volume que está sendo guardado.
Os mais comuns são:
Microsoft ACCESS;
LibreOffice BASE;
Microsoft SQL Server;
MySQL;
dBASE;
Para utilizá-los, é necessário conhecimento em tais linguagens e também em programação, o que pode ser um desafio para alguns profissionais.
Como visualizar o relacionar dados de bancos diferentes
Como dissemos no início desse artigo, caso você esteja lidando com muitas informações ou mesmo muitos bancos, pode ser que você se atrapalhe e faça uma modelagem incorreta, especialmente se você está usando linguagens de programação e não é muito familiarizado com elas.
Para isso, utilizar um software que tenha interface gráfica é extremamente mais simples.
O Analytics Plus, uma ferramenta de análise de dados, pode ser a solução perfeita para você. Com uma interface gráfica intuitiva, fazer a modelagem dos seus dados nunca mais será um problema.
Mesmo os mais leigos em programação ou em análise de dados têm facilidade em utilizar a ferramenta, já que com seu recurso no-code você pode enviar seus arquivos para o software e deixar que ele faça todo o trabalho para você.
Além disso, o Analytics Plus disponibiliza outros recursos, como:
Sugestões inteligentes para insights mais profundos;
Planejamento de custos e despesas com ativos de TI;
Otimização de processos de serviços para CSI (Continuous Service Improvement);
Relatórios automatizados;
Mecanismos de fórmula de alta octanagem ;
Experimente o Analytics Plus por 30 dias gratuitamente sem compromisso!