RCA et postmortem : transformer chaque incident en opportunité d’optimisation.

Imaginez que votre entreprise soit en pleine période de pointe des ventes, après avoir dépensé un budget colossal pour une campagne marketing.
Soudain, votre téléphone vibre : « Panne majeure. Les clients ne peuvent pas se connecter. » La salle de crise se remplit, les journaux défilent sans fin sur les écrans, et tout le monde est sous tension. Au lever du soleil, le service est rétabli, mais la grande question demeure : Que s’est-il passé ? Pourquoi cela s’est-il produit ? Et comment s’assurer que cela ne se reproduise plus jamais ?
C’est là qu’interviennent les post-mortems et l’analyse de la cause racine (RCA), deux pratiques complémentaires qui aident les équipes IT à transformer des incidents douloureux en opportunités de croissance.
Qu’est-ce qu’un post-mortem?
En informatique, un post-mortem est une analyse structurée réalisée après un incident. Son objectif n’est pas de désigner des coupables, mais d’apprendre.
Voyez-le comme un débriefing d’incident qui documente :
Résumé de l’incident – Qu’est-ce qui a mal tourné ?
Analyse de l’impact – Qui ou quoi a été affecté, et pendant combien de temps ?
Chronologie des événements – Quand les symptômes sont-ils apparus, quelles actions ont été entreprises, et dans quel ordre ?
Facteurs contributifs – Systèmes, processus ou événements externes ayant aggravé le problème.
Actions à entreprendre – Mesures concrètes pour éviter que cela ne se reproduise.
Un post-mortem bien mené vous donne l’histoire complète d’un incident, y compris la chronologie, l’impact et les facteurs contributifs.
Mais savoir ce qui s’est passé ne suffit pas.
Pour vraiment éviter que le même problème ne se reproduise, il faut aller plus loin et découvrir le pourquoi derrière l’incident.
C’est là qu’intervient l’analyse de la cause racine (RCA), qui transforme les conclusions du post-mortem en actions concrètes visant à traiter la véritable source du problème.
Qu’est-ce que l’analyse de la cause racine (RCA) ?
Alors qu’un post-mortem examine la situation dans son ensemble, la RCA va plus loin dans la recherche du pourquoi.
Il s’agit d’un processus systématique visant à trouver l’origine réelle d’un problème, au-delà de ses symptômes.
Parmi les techniques courantes de RCA, on retrouve :
Les 5 pourquoi (the 5 whys): Poser la question « pourquoi » à plusieurs reprises jusqu’à identifier la véritable cause racine.
Le diagramme de Fishbone (Ishikawa): Cartographier toutes les causes potentielles par catégories comme les personnes, les processus, les outils et l’environnement.
L’analyse de l’arbre de défaillances (Fault Tree Analysis): Utiliser une carte logique visuelle pour remonter aux causes ayant conduit à l’incident.
Dans le contexte de l’ITSM, la RCA est un élément essentiel de la gestion des problèmes, aidant les équipes non seulement à corriger les incidents, mais à les éliminer définitivement.
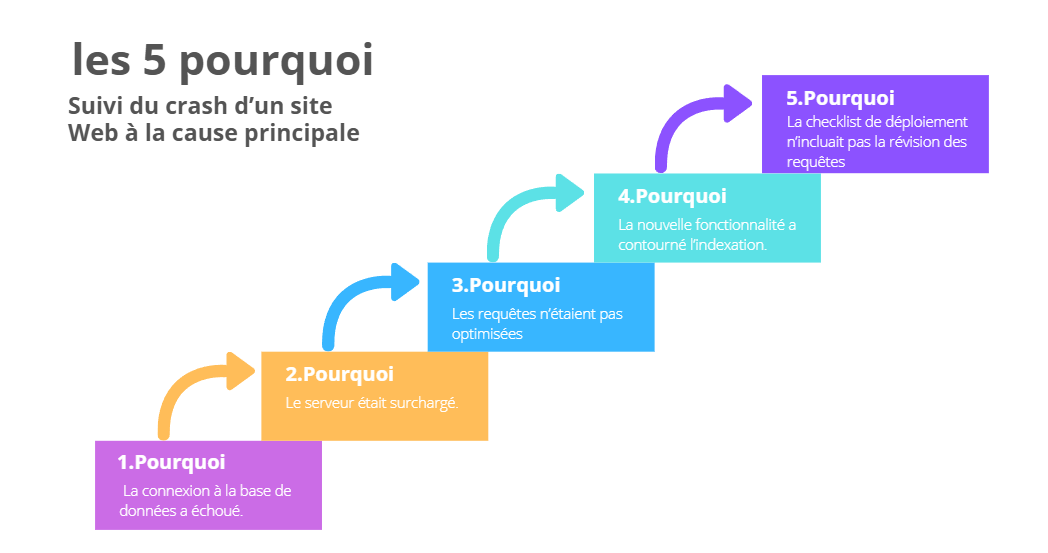
1. Les 5 pourquoi
La technique des 5 pourquoi est aussi simple que puissante : commencez par le problème et continuez à demander « pourquoi ? » jusqu’à découvrir la cause racine.
Comment ça fonctionne : vous posez la question « pourquoi ? » à chaque réponse obtenue, généralement cinq fois (parfois plus ou moins).
Exemple :
1. Pourquoi le site web est-il tombé en panne ? – Parce que la connexion à la base de données a échoué.
2. Pourquoi la connexion à la base de données a-t-elle échoué ? – Parce que le serveur était surchargé.
3. Pourquoi était-il surchargé ? – Parce que les requêtes n’étaient pas optimisées.
4. Pourquoi n’étaient-elles pas optimisées ? – Parce que la nouvelle fonctionnalité a contourné l’indexation.
5. Pourquoi a-t-elle contourné l’indexation ? – Parce que la checklist de déploiement n’incluait pas la révision des requêtes vers la base de données.
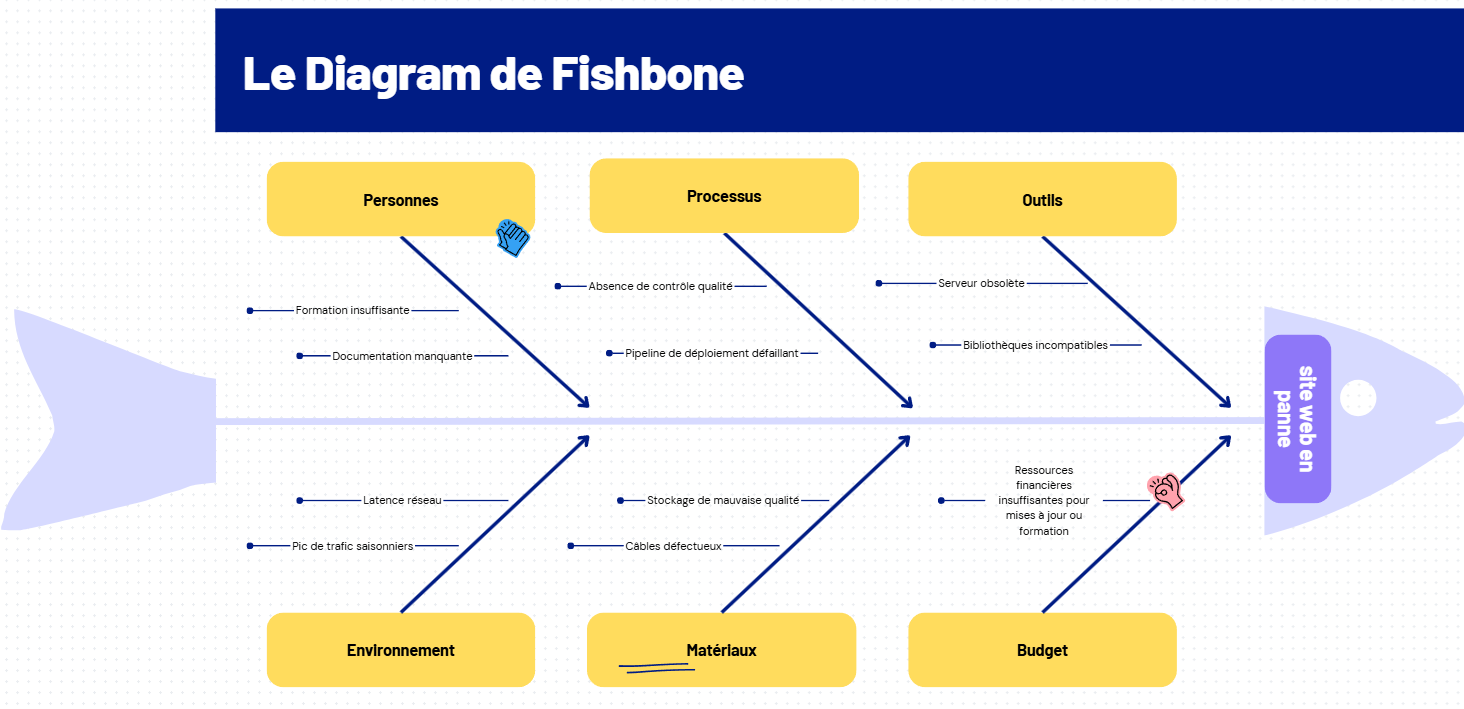
2. Le diagramme de Fishbone (Ishikawa) :
Le diagramme en arêtes de poisson, également appelé diagramme d’Ishikawa, est un outil visuel de brainstorming qui cartographie toutes les causes possibles selon différentes catégories.
Comment ça fonctionne : tracez une « colonne vertébrale » avec des branches pour des catégories comme Personnes, Processus, Outils, Environnement, Matériaux. Sous chacune, listez les facteurs contributifs possibles.
Exemple : pour une application lente, les catégories pourraient inclure :
Personnes – formation insuffisante, documentation manquante.
Processus – absence de contrôle qualité, pipeline de déploiement défaillant.
Outils – serveur obsolète, bibliothèques incompatibles.
Environnement – latence réseau, pics de trafic saisonniers.
Materiaux - Stockage, cables defectueux.
3. Analyse de l’arbre de défaillances (FTA)
L’analyse de l’arbre de défaillances utilise un diagramme logique pour retracer les événements ayant conduit à une défaillance du système.
Comment ça fonctionne : commencez par l’événement indésirable en haut (par ex. « Panne du système ») et descendez en cartographiant les causes à l’aide de portes logiques :
Portes ET (AND) – lorsque plusieurs conditions doivent être réunies pour que la défaillance se produise.
Portes OU (OR) – lorsqu’une seule condition suffit à déclencher la défaillance.
Exemple : une « panne du système » pourrait provenir d’une défaillance de la base de données OU d’un plantage de l’application, chacun pouvant avoir plusieurs facteurs contributifs.
Tableau récapitulatif des techniques RCA:
Technique | Description | Points forts | Advantages |
Les 5 pourquoi | Poser la question « pourquoi ? » de manière répétée jusqu’à trouver la cause racine. | Problèmes simples et linéaires avec une cause principale. | Rapide, peu d’effort, aucun outil spécifique requis. |
Le diagramme de Fishbone (Ishikawa) | Outil visuel qui organise les causes possibles par catégories (personnes, processus, outils, environnement, matériaux…). | Problèmes avec plusieurs causes possibles réparties entre différentes catégories. | Outil visuel de brainstorming, favorise la collaboration en équipe. |
Fault Tree Analysis (FTA) | Diagramme logique qui retrace les causes en utilisant des portes ET/OU | Systèmes à forte complexité ou critiques pour la sécurité, avec des causes interdépendantes. | Visualisation claire des dépendances ; aide à l’analyse des risques. |
Comment le post-mortem et les RCA fonctionnent ensemble ?
Le post-mortem et la RCA sont les deux faces d’une même pièce:
Le post-mortem répond à ce qui s’est passé et quand cela s’est produit.
La RCA répond à pourquoi cela s’est produit.
Un post-mortem peut révéler que le serveur de base de données a planté après un déploiement, lorsque la RCA permettrait de découvrir qu’un paramètre de configuration a été modifié manuellement, sans test adéquat, en raison d’une étape manquante dans la checklist de déploiement.
Conclusion
Les incidents sont inévitables. Mais ce qui distingue les équipes IT les plus performantes des autres, c’est la manière dont elles réagissent une fois la crise passée.
En combinant post-mortems et RCA, vous ne vous contentez pas d’éteindre les incendies — vous rendez votre infrastructure ignifuge.
Si votre outil ITSM prend en charge les post-mortems structurés et les workflows de gestion des problèmes, faites-en une pratique standard de vos opérations.
Chaque incident peut devenir une occasion de s’améliorer, de se renforcer et de gagner en rapidité.
Pour aller plus loin, des outils comme ManageEngine ServiceDesk Plus permettent d’intégrer ces pratiques directement dans votre flux IT. Ils centralisent la gestion des incidents, facilitent l’ouverture de tickets de problem management pour les RCA, offrent des tableaux de bord et rapports détaillés pour visualiser les causes racines, et automatisent le suivi des actions correctives.
Ainsi, votre infrastructure ne se contente plus de résister aux incidents: elle devient proactive, optimisée et prête à prévenir les problèmes avant qu’ils n’impactent vos utilisateurs.