
Si vous êtes propriétaire d'une entreprise, vous connaissez la valeur d'un réseau sain et vous savez à quel point une panne de réseau est préjudiciable à votre activité. Mais les problèmes de réseau sont inévitables. La forte dépendance à l'égard des réseaux pour répondre à l'évolution constante des besoins des clients et de l'utilisation interne pèse lourdement sur le réseau.
Cela rend les réseaux vulnérables aux problèmes courants tels que les temps d'arrêt soudains et imprévus, l'utilisation élevée des ressources et les dysfonctionnements matériels.
Les goulets d'étranglement ne sont donc pas nouveaux pour un réseau, mais la clé réside dans la façon dont vous atténuez la fréquence des problèmes.
Deux domaines d'action pour réduire les problèmes de réseau
- Le temps moyen de réparation (MTTR) : Il s'agit d'une mesure du temps moyen nécessaire pour réparer une panne et rétablir le réseau à la normale. Une valeur MTTR élevée peut vous nuire financièrement et vous obliger à payer des pénalités pour non-respect des accords de niveau de service. Il est donc essentiel de disposer d'un système de gestion des pannes de réseau efficace et robuste.
- Trouver la cause primaire : Les réseaux sont des systèmes compliqués composés d'une grande variété de dispositifs et d'interfaces, ce qui rend très difficile pour les administrateurs réseau de localiser précisément la cause primaire des goulets d'étranglement du réseau. Le temps écoulé pour localiser les problèmes de réseau signifie que le MTTR de votre réseau est en constante augmentation, ce qui peut affecter votre activité à terme.
La voie à suivre : L'analyse des causes primaires dans la surveillance du réseau
L'identification des problèmes est le plus grand défi à relever lorsqu'on essaie de réduire le MTTR. Le maintien d'un MTTR faible permet de conserver la confiance des clients dans votre entreprise, et de protéger votre entreprise de l'effondrement.
Afin de vous permettre d'analyser en détail les
performances du réseau, nous avons introduit la fonction
d'analyse des causes primaires (RCA) dans OpManager.
Grâce à la fonction RCA, vous pouvez obtenir une visibilité complète des données de surveillance du réseau de tous vos appareils, interfaces et URL dans une console centralisée.
Grâce à une visibilité complète des informations de surveillance pertinentes, le temps nécessaire à l'analyse des performances et à la détermination de la cause primaire est considérablement réduit, ce qui se traduit par une valeur MTTR globale plus faible.
Fonctionnalités importantes
Comparez les moniteurs graphiquement
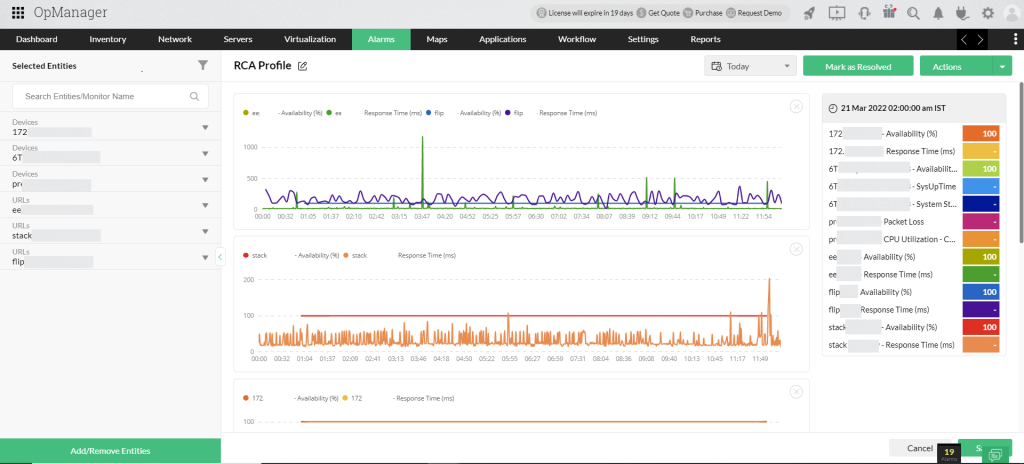
Il suffit de faire glisser et de déposer les mesures de performance des dispositifs, interfaces ou URL sélectionnés pour que RCA construise automatiquement un graphique avec des courbes de performance, chacune représentant un moniteur.
Comparez les performances de plusieurs périphériques sur une seule mesure, ou plusieurs mesures pour un seul périphérique, le tout dans une seule vue.
Enregistrez vos interprétations
Pour trouver la cause primaire, il faut rassembler les données de surveillance nécessaires, les comparer et les analyser en détail, et enfin enregistrer vos interprétations. Grâce à l'option d'annotation, vous pouvez enregistrer vos résultats et ajouter des notes de résolution une fois que vous avez trouvé la cause racine. Si vous souhaitez interrompre votre analyse à mi-chemin, vous pouvez enregistrer vos interprétations jusqu'à ce point et les sauvegarder.
Lorsque vous revenez, vous pouvez reprendre à partir du point où vous vous êtes arrêté. Cela est également très utile lorsque plusieurs membres de l'équipe collaborent à la recherche de la cause primaire. Par exemple, un administrateur réseau peut effectuer un RCA et enregistrer ses conclusions, et plus tard, un responsable de haut niveau peut lire les notes d'annotation et prendre des décisions basées sur des données pour modifier la configuration du réseau.

Effectuer un RCA pour des groupes
Cette option est utile pour
analyser collectivement les performances d'un ensemble de périphériques ou d'interfaces. Par exemple, lorsqu'un réseau particulier dans un site spécifique tombe en panne, vous pouvez sélectionner le réseau (groupe), ce qui fait apparaître automatiquement les périphériques spécifiques à ce groupe, et vous pouvez commencer à analyser les problèmes de performance immédiatement.
Comment le RCA simplifie-t-il la surveillance du réseau?
Sans RCA, l'identification de la cause primaire est un véritable casse-tête. Par exemple, imaginez qu'une alarme soit déclenchée lorsqu'un routeur central de votre réseau tombe en panne. Vous devez examiner en détail les données de l'alarme et visiter la page d'instantané de l'appareil pour mieux comprendre le problème.
Cette méthode peut sembler simple lorsque vous devez effectuer une analyse des causes primaires pour un seul appareil. Mais que se passe-t-il si plusieurs appareils de votre réseau tombent en panne et que cela entraîne une défaillance complète du réseau ?

Avec RCA, vous pouvez afficher les graphiques de performance de divers moniteurs dans un module centralisé et les comparer tous dans un seul volet. Avec un ensemble complet d'informations sur votre écran, l'analyse des performances et la localisation de la cause première d'un problème deviennent une tâche facile.
RCA gagne du terrain : Un cas d'utilisation réel
Disons que les utilisateurs signalent une vitesse de chargement lente lorsqu'ils accèdent à votre application. Pour résoudre complètement le problème, vous devez identifier la cause réelle et prendre des mesures correctives.
Tout d'abord, vous pouvez suivre l'utilisation du processeur et de la mémoire de votre serveur d'application pour comprendre si la lenteur du chargement est due à une surcharge du serveur. En écartant cette possibilité, vous pourrez analyser les autres causes possibles.
Une vitesse de chargement lente peut également survenir lorsque votre serveur d'applications attend le périphérique de stockage qui abrite votre système de fichiers. Vous pouvez vérifier les IOPS, la latence, le débit et l'utilisation de votre périphérique de stockage pour comprendre si le problème est dû à un périphérique de stockage sous-performant et sur-utilisé.
Parfois, la lenteur du chargement peut également être due à des problèmes de bande passante dans les interfaces reliant le serveur et votre environnement de stockage. La surveillance des métriques Interface Rx et Interface Tx vous aidera à localiser les goulots d'étranglement, le cas échéant.
Ainsi, lorsque vous rencontrez un scénario complexe tel que celui évoqué ci-dessus, vous devrez comparer les performances de plusieurs composants réseau. RCA fournit la plateforme permettant de rassembler toutes les données en une seule vue, de les analyser, d'écarter les possibilités et de déterminer la cause exacte des problèmes en moins de temps.
Apprenez-en davantage sur OpManager et
téléchargez une version d'essai gratuite de 30 jours. Vous pouvez également faire l'expérience d'une démo gratuite en ligne, ou programmer une
démo gratuite et personnalisée avec nos experts qui pourront répondre à toutes vos questions sur le produit.
Source : Bolster network monitoring with root cause analysis