Navigating container monitoring: Key challenges and practical solutions
It's no secret: Containers have fundamentally reshaped application deployment, driving agility and scalability. However, they've also introduced a new set of complexities in container monitoring that often outpace traditional methodologies. In this blog, we'll explore the core challenges in container observability and outline pragmatic strategies for ensuring a robust and performance-driven containerized environment.
Challenge #1: The transient nature of containers (ephemerality)
Containers are inherently ephemeral, with their life cycles often measured in seconds. This dynamism creates observability gaps for monitoring tools designed for static infrastructures.
Practical solutions:
Implement real-time monitoring solutions that provide immediate insights into container health and performance to prevent blind spots.
Leverage Kubernetes-native observability tools like Prometheus or comprehensive container monitoring tools like ManageEngine Applications Manager for effective container life cycle tracking.
Utilize distributed tracing (OpenTelemetry, Applications Manager) to maintain visibility across short-lived container instances.
Why it matters: Without real-time monitoring, troubleshooting ephemeral containers becomes impossible. This can lead to undetected failures and degraded performance.
Challenge #2: Monitoring at scale
Large-scale deployments, involving hundreds or thousands of containers across clusters, can overwhelm conventional monitoring systems, resulting in alert fatigue and inefficient troubleshooting.
Practical solutions:
Employ auto-discovery mechanisms to detect new container instances without manual configuration dynamically.
Utilize AI-driven anomaly detection to minimize false positives and reduce alert noise.
Optimize log aggregation and centralization for efficient data querying and analysis.
Why it matters: Without automated scalability, IT teams often struggle to track performance bottlenecks. This can cause slow response times and inefficient resource utilization.
Challenge #3: Managing log and metric overload
The sheer volume of logs and metrics generated by containers can lead to significant storage and processing overhead.
Practical solutions:
Implement log sampling and retention policies to prioritize relevant data.
Utilize log aggregation platforms (e.g., ELK Stack, Fluentd, Loki) to streamline log management.
Consider edge-based monitoring solutions to process data locally and reduce cloud ingestion costs.
Why it matters: Without proper log management, IT teams can end up wasting time sifting through log files. This makes it harder to detect critical performance issues.
Challenge #4: Achieving observability in multi-cloud and hybrid environments
Unified monitoring across on-prem, hybrid, and multi-cloud deployments presents a significant challenge due to the lack of standardization and interoperability.
Practical solutions:
Utilize cloud-agnostic monitoring tools like ManageEngine Applications Manager to collect and analyze data across environments.
Ensure consistent logging and tracing frameworks across all containerized workloads.
Implement service meshes (Istio or Linkerd) to enhance inter-service communication visibility.
Why it matters: A lack of unified monitoring creates blind spots, making it difficult to correlate issues and optimize performance across multiple environments.
Challenge #5: Addressing security and compliance risks
Containers introduce unique security vulnerabilities and require rigorous monitoring to maintain compliance with industry standards.
Practical solutions:
Deploy runtime security monitoring tools (e.g., Falco, Sysdig Secure) to detect real-time anomalies.
Implement container image scanning (e.g., Trivy, Clair) to identify vulnerabilities before deployment.
Enforce role-based access control (RBAC) and least privilege policies to mitigate unauthorized access.
Why it matters: Weak security measures can expose containers to attacks, leading to data breaches and non-compliance with regulatory standards.
While container monitoring presents unique challenges, a strategic approach with the right tools can achieve comprehensive observability, improved performance, and enhanced security. By embracing real-time monitoring, automation, and intelligent analytics, teams can proactively address issues and ensure a seamless user experience. It's about refining our monitoring stack to align with the dynamic nature of cloud-native environments.
Container monitoring with ManageEngine Applications Manager
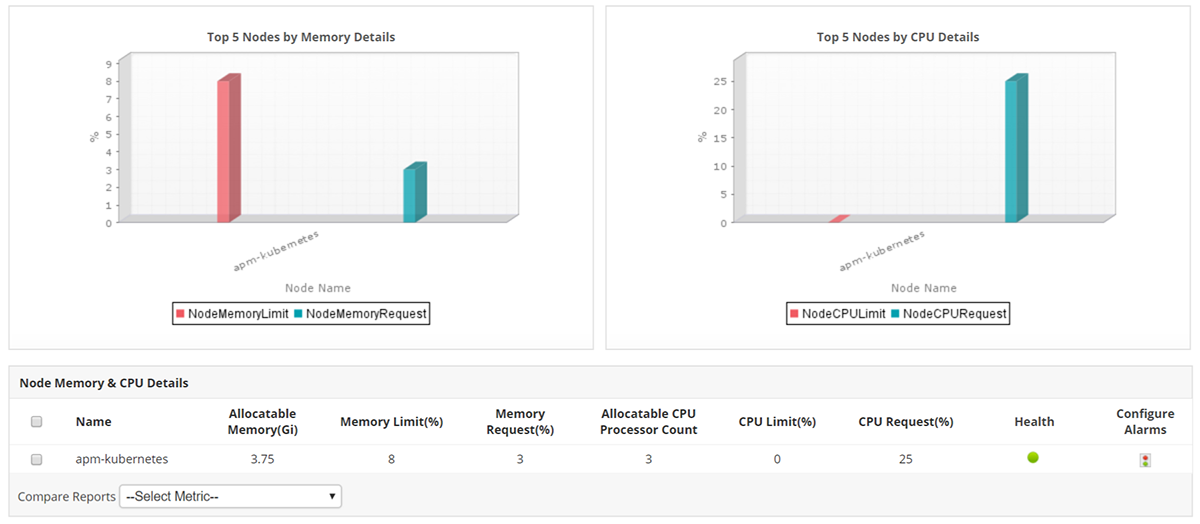
ManageEngine Applications Manager offers a robust solution for organizations seeking to gain comprehensive visibility into their containerized environments and plays a significant role in helping them effectively monitor their containerized environments. Here's a breakdown of its capabilities in this area:
Key capabilities of Applications Manager
Comprehensive container monitoring:
Applications Manager provides in-depth monitoring for popular container technologies like Docker, OpenShift, and Kubernetes.
It offers visibility into the health and performance of containers, ensuring that applications running within them are operating optimally.
Key performance indicator (KPI) tracking:
The tool enables users to track essential container KPIs, including resource utilization (CPU, memory, disk, network), response times, and error rates.
This data helps identify performance bottlenecks and potential issues before they impact end-users.
Auto-discovery:
Automatically discovers new containers and services, ensuring full coverage of your dynamic infrastructure, regardless of where they spin up
Kubernetes monitoring:
Given the complexity of Kubernetes orchestration, Applications Manager offers specialized monitoring capabilities for Kubernetes clusters.
It allows administrators to monitor various Kubernetes components, such as pods, nodes, and services, to provide a holistic view of the cluster's health.
Docker monitoring:
Applications Manager provides granular visibility into the performance of individual Docker containers. This is crucial for understanding the resource consumption and behavior of each containerized application.
It monitors key metrics like CPU usage, memory utilization, network I/O, and disk I/O at the container level.
OpenShift Monitoring:
Applications Manager monitors the overall health of OpenShift clusters, providing insights into the performance of nodes, pods, and services.
It helps identify potential issues that could impact the availability and performance of applications running on OpenShift.
Real-time insights and alerting:
Applications Manager provides real-time insights into container performance, enabling teams to quickly identify and address issues.
It also offers robust alerting capabilities, notifying administrators of critical events and performance deviations.
It also helps reduce manual intervention by automating container actions in case of threshold violations.
Troubleshooting and root cause analysis:
The tool provides detailed diagnostics and root cause analysis capabilities, helping teams pinpoint the source of performance problems.
This speeds up troubleshooting and reduces mean time to resolution (MTTR).
ML-based anomaly detection helps recognize performance degradation before end users are affected.
Advanced analytics:
Applications Manager helps understand historical performance and performance trends by collecting and aggregating data over time.
Forecast reports help anticipate the resource consumption and growth that organizations can use to plan capacity and right-size their resources.
Integration with Istio service mesh
Monitor every aspect of your Istio service mesh environment, including latency, traffic routing, resource usage and service health.
Thank you for sharing valuable information.