Qu’est-ce que PyTorch ? Introduction au framework préféré des chercheurs en IA

L’IA transforme profondément notre manière d’interagir avec les technologies. Des assistants vocaux aux voitures autonomes, en passant par les outils de traduction automatique ou de diagnostic médical, l’IA s’impose désormais dans presque tous les secteurs. Derrière ces avancées se cachent des frameworks puissants permettant aux chercheurs et aux ingénieurs de concevoir, tester et déployer des modèles d’apprentissage automatique sophistiqués.
Parmi ces outils, PyTorch s’est rapidement imposé comme un choix privilégié, notamment dans le monde de la recherche. Développé par Meta AI (anciennement Facebook AI Research), PyTorch séduit par sa flexibilité, sa simplicité d’utilisation et son alignement étroit avec le langage Python, déjà largement utilisé en science des données.
Dans cet article, nous vous proposons une introduction complète à PyTorch : ce qu’il est, pourquoi il est si apprécié, et comment il s’intègre dans le paysage de l’apprentissage profond aujourd’hui.
Qu’est-ce que PyTorch ?
PyTorch est un framework open source destiné au développement de modèles de machine learning, avec une spécialisation marquée dans l’apprentissage profond (deep learning). Il permet de construire des réseaux de neurones, de les entraîner, de les évaluer et de les déployer facilement dans des environnements de recherche ou de production.
L’une des caractéristiques les plus marquantes de PyTorch est sa programmation impérative et dynamique, qui offre une grande souplesse dans la conception des modèles. Contrairement à certains frameworks plus rigides, PyTorch permet de modifier la structure des réseaux à la volée, ce qui est particulièrement utile dans un contexte de recherche expérimentale.
Le workflow PyTorch : Étapes clés pour entraîner un modèle d’apprentissage profond
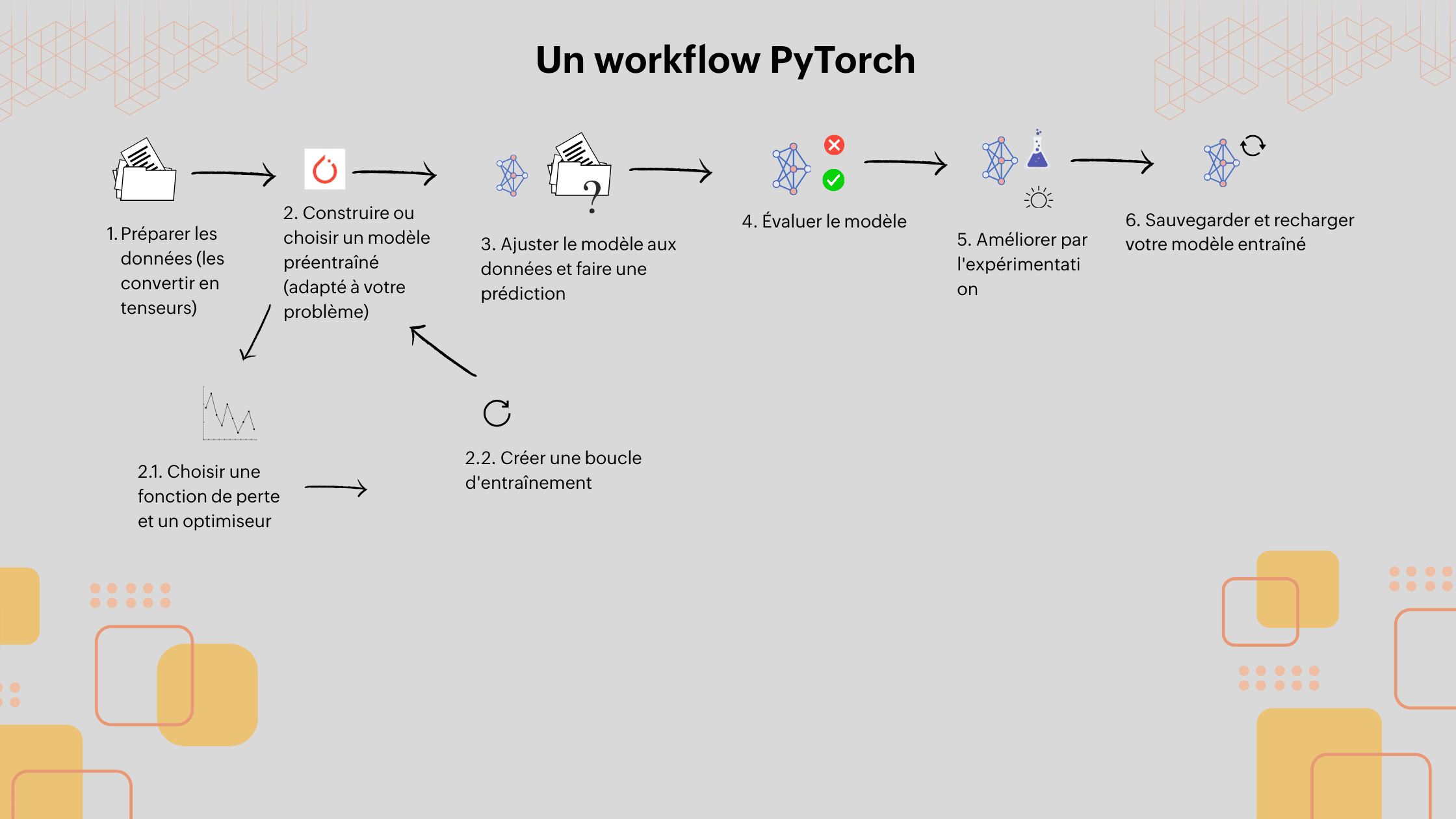
ravailler avec PyTorch suit une série d’étapes structurées permettant de construire, entraîner, évaluer et améliorer un modèle de deep learning. Voici un aperçu du workflow typique avec PyTorch :
Préparation des données : La première étape consiste à préparer les données en les transformant en tensors, le format de données natif utilisé par PyTorch. Ces tensors permettent de manipuler facilement les entrées du modèle.
Construction ou sélection d’un modèle pré-entraîné : Selon votre problématique, vous pouvez soit construire un modèle sur mesure, soit utiliser un modèle pré-entraîné disponible dans l’écosystème PyTorch.
2.1 Choisir une fonction de perte et un optimiseur : Ces éléments sont essentiels pour évaluer la performance du modèle et ajuster ses paramètres.
2.2 Créer une boucle d’entraînement : C’est le cœur de l’apprentissage supervisé. Elle permet d’entraîner le modèle sur les données en calculant les pertes et en mettant à jour les poids.
Ajuster le modèle aux données et faire une prédiction : Une fois la boucle d’apprentissage en place, le modèle est entraîné sur les données, puis utilisé pour prédire des résultats.
Évaluer le modèle : Après l’entraînement, il est important d’évaluer les performances du modèle à l’aide de données de test. Cela permet de mesurer sa précision, sa robustesse et sa capacité à généraliser.
Amélioration par expérimentation : Cette étape consiste à affiner le modèle à travers des tests, des ajustements d’hyperparamètres, l’ajout de couches, ou encore la modification des données d’entrée.
Sauvegarde et rechargement du modèle : Une fois satisfait des performances, il est essentiel de sauvegarder le modèle entraîné afin de pouvoir le réutiliser ultérieurement sans avoir à le réentraîner.
Pourquoi PyTorch est-il autant utilisé par les chercheurs ?
Programmation dynamique : La principale force de PyTorch réside dans sa gestion dynamique des graphes de calcul. Cela signifie que le modèle est défini au moment de l’exécution, et non à l’avance. Cette approche rend le code plus intuitif et plus facile à déboguer, notamment pour les chercheurs qui expérimentent constamment avec de nouvelles architectures.
Syntaxe simple et naturelle : PyTorch est construit autour de Python, ce qui le rend simple à apprendre et rapide à prendre en main, même pour les non-développeurs. Sa syntaxe proche de NumPy permet une transition en douceur pour les data scientists et les étudiants en IA.
Fort soutien académique : Grâce à son orientation recherche, PyTorch est devenu le framework dominant dans les publications scientifiques. Il est largement utilisé dans les universités, les laboratoires et les projets open source. Il facilite l’expérimentation rapide, la reproductibilité des résultats et l’adoption de techniques de pointe.
Accélération GPU native : PyTorch intègre CUDA, l’outil de calcul parallèle de NVIDIA, ce qui permet un entraînement rapide des modèles sur des GPU. Cette compatibilité native facilite le développement de modèles à grande échelle.
Écosystème riche : Le framework s’accompagne d’une suite d’outils complémentaires :
TorchVision pour la vision par ordinateur
TorchText pour le traitement du langage naturel
TorchAudio pour l’analyse audio
PyTorch Lightning pour structurer les projets
TorchServe pour le déploiement de modèles en production
Quelques cas d’usage de PyTorch
PyTorch est utilisé dans de nombreux domaines, notamment :
Vision par ordinateur : détection d’objets, reconnaissance faciale, segmentation d’images.
Traitement du langage naturel (NLP) : traduction automatique, résumé de texte, génération de texte.
Génération d’images et de sons : réseaux antagonistes génératifs (GAN), modèles de diffusion.
Recherche biomédicale : diagnostic assisté par IA, classification d’imagerie médicale.
Apprentissage par renforcement : robotique, jeux, simulations.
PyTorch vs TensorFlow
Pendant longtemps, TensorFlow, développé par Google, était le leader incontesté. Mais PyTorch a su séduire la communauté académique par son approche plus intuitive et plus proche du développement Python natif.
Aujourd’hui, PyTorch est le framework préféré dans le monde de la recherche, tandis que TensorFlow conserve une forte présence dans certaines applications industrielles à grande échelle.
Conclusion
PyTorch s’impose comme un outil de référence dans le développement de solutions d’intelligence artificielle modernes. Sa flexibilité, sa simplicité d’utilisation, son écosystème riche et sa compatibilité avec les standards de la recherche en font un choix naturel pour tous ceux qui souhaitent travailler sur des projets d’IA, que ce soit à des fins académiques, expérimentales ou industrielles.
Apprendre PyTorch, c’est se donner les moyens de mieux comprendre les mécanismes de l’intelligence artificielle et de participer activement à son évolution.