
Kubernetes, one of the most popular container management systems, automates the work necessary for deploying and scaling a containerized application by managing a large number of interdependent microservices. Additionally, it allows for the migration and deployment of containerized applications across different platforms in a multi-cloud environment.
A recent survey conducted by Red Hat reveals that about 70% of IT leaders work for organizations that use Kubernetes, also commonly known as K8s, as there are regular updates by the community that populates the ecosystem with the latest solutions. However, the constant growth of microservices within the Kubernetes platform gives rise to a multitude of problems that could make your business-critical applications unavailable to end users. Even though Kubernetes is renowned for deploying applications virtually anywhere, it also faces a backlash for having too many components within its network. A major drawback with Kubernetes is that even a tiny service disruption within the cluster network can shut down the entire operation.
Therefore, it is crucial for IT admins to be aware of any difficulties that may arise in Kubernetes. This article addresses various challenges that IT administrators face with the K8s systems and how a Kubernetes monitoring tool overcomes them.
Common issues with Kubernetes
1. Inefficient resource utilization
The majority of Kubernetes system problems are caused by the container manager’s resources being configured incorrectly. Whenever a workload is scheduled, the container can request the required amount of CPU and memory resources. The Kubernetes scheduler then allocates the right node to the pod that can take up the task based on the amount of resources requested.
A value is generally specified to ensure that Kubernetes allocates enough nodal resources to a pod without exceeding the limit. However, when a container allocates more resources than are available, the application slows down and over-usage results. Similarly, under-usage results when the requested resources allocate more than what is being utilized, which also tends to slow down the application.
In addition, a limit can also be set to restrict the amount of resources the container can access. These constraints are preconfigured within the pod to ensure that the workload is executed without any delay and doesn’t impede the progress of others. Whenever a CPU or memory request is made, the usage limit is set at a value so that there is enough room to accommodate an excessive use of such resources.
But what if the pod consumes more than what it is allowed to? It can lead to two major Kubernetes problems:
CPU throttling
CPU throttling occurs when the CPU usage nears the CPU limit. Since the limit specifies the maximum CPU utilization available to the pod, the application won’t get access to an adequate amount of resources that are required to run the workload. The pod might subsequently shut down and restart. As a response mechanism, the CPU is throttled to minimize CPU utilization, which slows down the application.
OOMKilled
The OOMKilled error code occurs whenever the container consumes more memory resources than allocated. As the memory usage tries to exceed the memory limit, the associated process gets OOMKilled (Out of Memory Killed), or terminated. The kubelet may then restart the pod and try to allocate memory based on the request. If the pod restarts, there will be certain delay due to loading time that will impact the container application.
Often a result of poor configuration, CPU throttling and OOMKilled errors can be resolved by optimizing or removing the resource limit. However, in a large container infrastructure, identifying these issues can be a huge challenge as it often reflects as latency and a performance delay. Because there are numerous Kubernetes elements involved, it may prove difficult to navigate through the network and limit the anomalies.
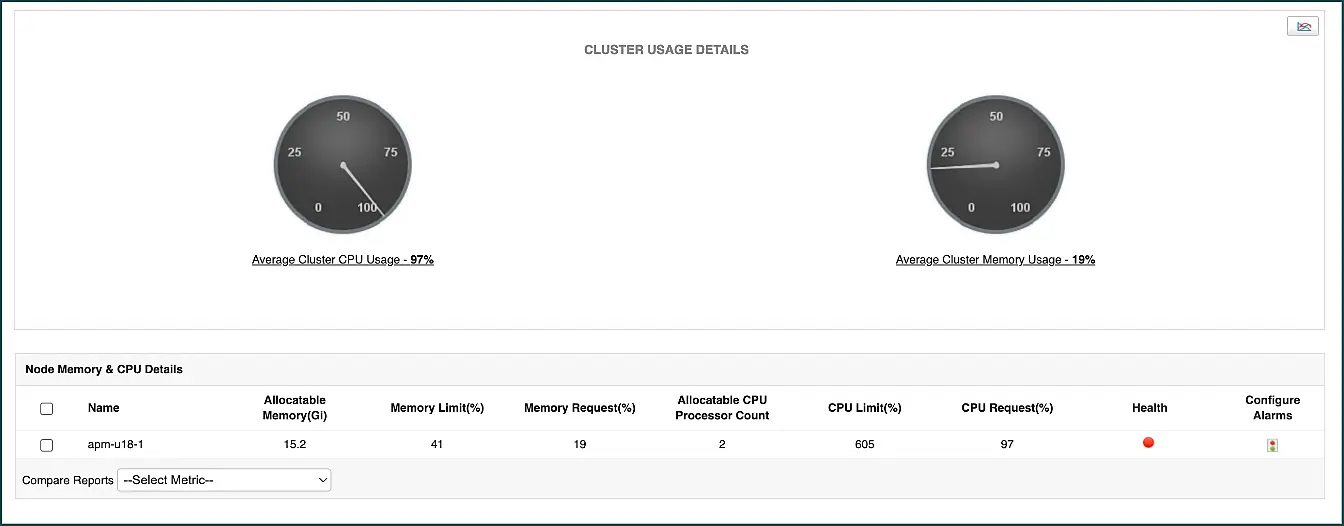
Kubernetes monitoring software like ManageEngine Applications Manager collects data to display the CPU and memory limit value for each pod. This solution’s monitor also tracks the status of the pod, the cluster’s CPU and memory usage activity, and the allocatable CPU processor counts for each node. In addition, the monitor displays graphs that show the Top 5 nodes or pods which can easily identify the components that have exceeded their request limit.

By collectively analyzing these data, decisions can be made to remove or alter the limit imposed on the pods and help counter the CPU throttling and OOMkilled error code.
2. CrashLoopBackOff error
Whenever there are insufficient CPU or memory resources, pods might get terminated without being able to get scheduled to a node. This prompts the kubelet to restart the failed pod which is then prone to crash again as well as enter a loop that triggers the CrashLoopBackOff error code. Each time the container backs off for a reboot, the loading time increases exponentially. The CrashLoopBackOff error code can also appear whenever a container starts for the first time and enters a loop. Some of the other culprits responsible for the CrashLoopBackOff error are misconfigurations, mismatch of resource names, locked resources, and connectivity issues.

As mentioned earlier, having visibility into the resource usage and configuration of your container can help prevent your pods fro, falling into the restart loop. Applications Manager’s Kubernetes container monitor provides the status of each container and the number of times they have restarted over a period of time. These details can be analyzed to help identify a potential CrashLoopBackOff error that could be hard to spot otherwise.
3. ErrImagePull error
ErrImagePull is another error that occurs whenever a pod isn’t able to pull the requested image from the container registry. The pod then goes to the ErrImageBackOff state. A reason for this error is when the container image name specified in the container pod is incorrect. Retrieving the wrong image can also lead to pod failure which can prove fatal to application operations.
Employing the services of a Kubernetes monitoring tool like Applications Manager helps admins perform a thorough check on their container system to identify potential mismatches. They can then edit the pod specification to provide the correct name and manually pull the image. You can also view the total number of images available in each node within our Kubernetes dashboard.
4. Service disruption
There are multiple Kubernetes services responsible for facilitating communication across different nodes within a cluster network. A disruption in any of these services could impact the sharing of resources across containers as the node will not be accessible. There can be multiple reasons for service disruption that could have a huge impact on network connectivity.
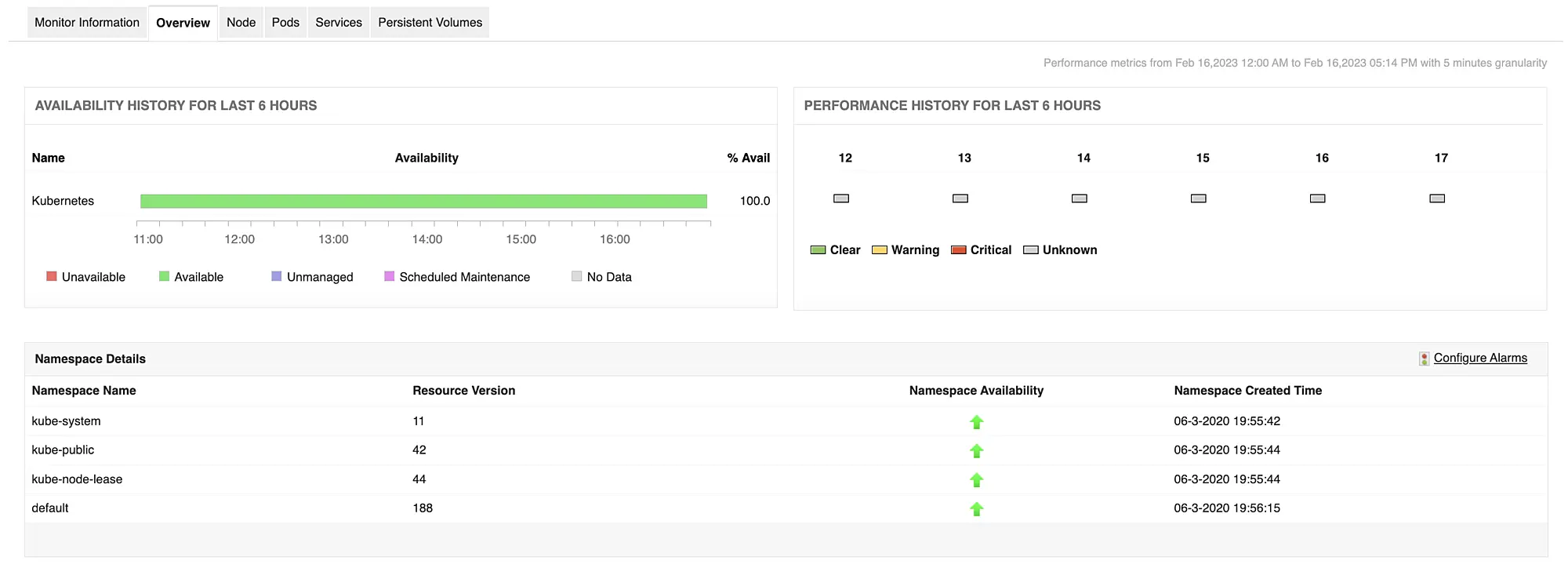
Sometimes services fail at the creation stage and these can be hard to pinpoint, especially when you are working with a large number of them. This is another example of where Application Manager’s Kubernetes service monitoring comes in handy as it lists out every container service along with the associated namespace and application details. It also displays the protocol, type, and target port of each service which can be useful in ensuring that your pods are listening to the right service. You can also keep track of the associated namespaces of each service as any discrepancies can also result in failure.
5. Unavailable PVs for binding
For efficient storage management, it is important to keep track of the availability status for each Persistent Volume (PV) storage unit and Persistent Volume Claim (PVC) after being used by a pod. Often, when a PVC is deleted, the PV might still remain unavailable after restart as old pod data might still be stored. Using our Kubernetes monitor, users can identify unavailable PV and PVCs to make necessary rectifications. In addition, our tool also displays the storage class of each PVC as it is important to ensure that they are properly defined. PVCs without a defined storage class will fail.

It is also crucial to ensure that the right PV is referenced to pods. If there isn’t enough storage capacity to support the claim, it could result in PV failure. By monitoring the PVCs with Applications Manager, users can gain an overview into the amount of storage requested by PVCs and check if they can be accommodated by the bound PV.
6. Application unavailability
Each node is confined to a certain amount of pods that can be allocated for resource utilization. Exceeding this maximum limit might make the node inaccessible to other pods whose workload disruption could directly affect the containerized application itself.
Our tool for K8s monitoring aids in preventing application unavailability by breaking down the maximum available pod count and used pod count for each Kubernetes node. Admins can take quick action to avoid any disruptions by designating that alarms go off whenever the pod count nears the limit.
Applications Manager’s Kubernetes monitoring tool benefits:
-
Complete visibility into a Kubernetes cluster with in-depth statistics and activity status of nodes, pods, services, and PVs.
-
Real-time health and availability of different Kubernetes components and namespaces.
-
Visual graphs that sort out different nodes and pods that can aid in efficient resource management.
-
Agentless monitoring that can be configured in just a few minutes.
-
Fault management with instantaneous alerts that trigger whenever a parameter crosses the desired threshold.
-
Intelligent forecast reports that can help predict Kubernetes resource growth trends based on historical data.
Learn more about the best practices of Kubernetes monitoring.
Conclusion
Navigating through common Kubernetes obstacles using a comprehensive monitoring tool like Applications Manager enables you to get the most out of your container management system. Applications Manager digs deep into your Kubernetes system to help shine light on any issue that might come your way.
Applications Manager also monitors other components of your IT infrastructure, such as cloud services, databases, servers, hardware, services, and even the application itself. With support for over 150 technologies, Applications Manager is the one-stop monitoring solution for your application-based business.
Learn more about Applications Manager by exploring on your own with a 30-day, free trial. You can discover all the functionalities of the Kubernetes monitor and understand how it fits within your organization. You can also receive answers to your product questions from our solution experts by scheduling a free, personalized demo.