
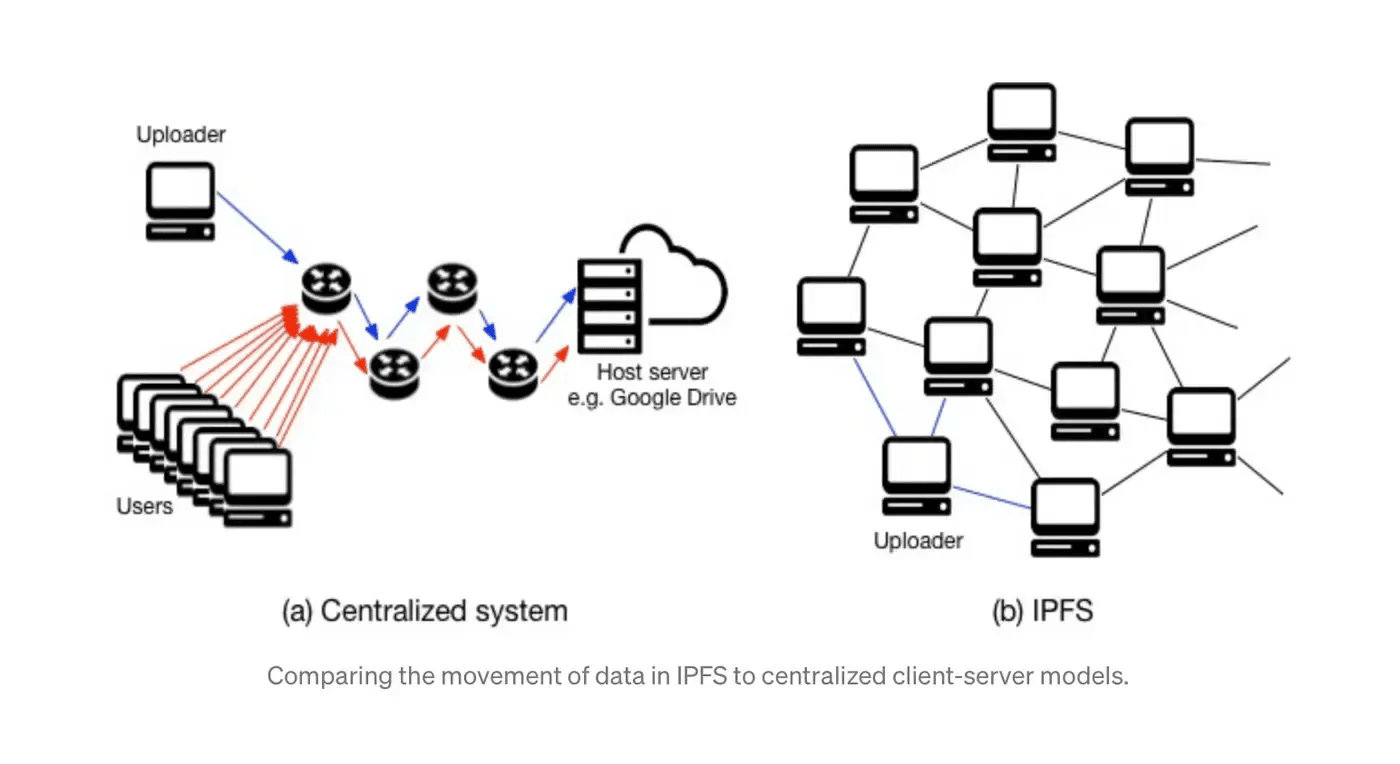
Welcome to the universe of the IPFS, a protocol and peer-to-peer network that helps users retrieve and store files based on the content rather than the location of the requested information. It was founded by Juan Benet in 2015, who later founded Protocol Labs. IPFS enables its users to store and share content similarly to the way BitTorrent does. Compared to the traditional system of storing information on a centrally located server, IPFS is a decentralised network that helps its users and operators hold a portion of data.
Data these days is of utmost importance; huge tech companies, or any company for that matter, need access to their data to make informed decisions, improve operations, and gain a competitive edge. When a central server goes offline, access to critical information is disrupted, creating a roadblock for the smooth functioning of the organization. Moreover, data centralization often leads to data monopolies, where a handful of corporations control vast amounts of personal and public information, raising concerns about privacy and surveillance. This is where IPFS can come in and help to decentralize data.
Ref: https://symphony.is/about-us/blog/introduction-to-ipfs
How does it work?
IPFS is the result of combining multiple blocks commonly used to build distributed applications into a distributed storage application. In IPFS, data is divided into blocks, which can be identified with a unique identifier called the content identifier (CID). These are generated by combining the hash of the content along with its codec. A codec is a device or a program that encodes or decodes a data stream or signal.
Once computed, these CIDs can help you fetch data based on the content rather than the location, and the CID of the data received can be computed and compared to the CID requested to double-check that the data is what was requested. The general way to store files in the decentralised system is to use InterPlanetary Linked Data (IPLD), which can chunk and link data too big to fit in a single block. IPFS also supports storing compressed files in Content Addressable aRchive (CAR) format. This is similar to the format of compressed TAR and ZIP files.
In the IPFS network, nodes play a pivotal role in storing, sharing, and retrieving data. Each node is a participant in the decentralised system and acts as a peer that can host, request, or transfer files. All files in IPFS are organized using a structure called the distributed hash table (DHT). The hash table is distributed because no single node in the network holds the entire table. Instead, each node stores a subset of the hash table as well as information about which nodes are storing other relevant sections.
The DHT acts as a decentralised directory that helps locate the peers in the network storing the data you need. Imagine it as a massive table spread across many nodes, where each entry maps a piece of data (identified by its CID) to the peers (IP addresses) that have it. This distributed approach ensures that data can be efficiently located without relying on a central server, making the system more robust and resilient.
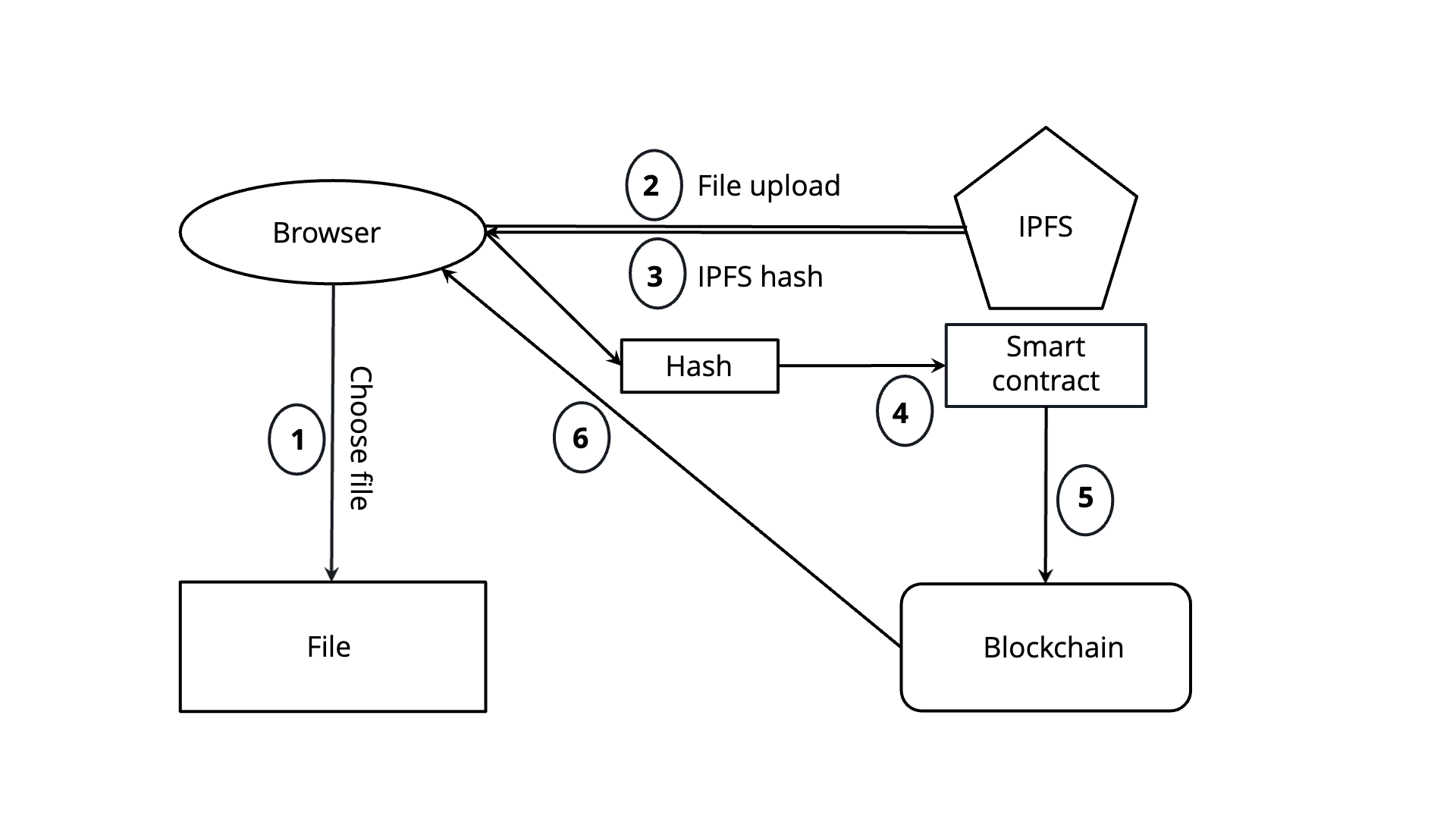
Uploading files
Uploading files to IPFS involves a few key steps to ensure that the file is properly added to the decentralized network. To interact with the IPFS network, you need to have an IPFS node running. There are several ways to do this:
-
Install the IPFS desktop app on your local machine.
-
Install the IPFS client command line tool.
-
Use a public gateway to access or push files to the IPFS network.
Once you have the IPFS node up and running, the next steps are quite straight forward. You will have to add a file to the network that, on successful upload, will return a CID to you. This CID can then, in turn, help you fetch the same file whenever needed. Uploading a file to IPFS is a simple yet powerful way to store data in a decentralized manner. Whether using your own node or leveraging a third-party pinning service, IPFS allows you to contribute to a distributed and resilient web. By using CIDs to identify files, IPFS eliminates the need for centralized servers, making data more accessible and censorship-resistant.
For you to access a file that is present in the network, you will need access to the CID. Once you have the identifier, you can either access it from a public gateway by visiting the specific URL and adding the CID to the path, or you can make sure that your node is running on your local machine and use the get command to download the file on your device.
Downloading files
Fetching files from IPFS is simple and can be done using several methods, depending on your setup and preferences. Whether using a public IPFS gateway, your own IPFS node, a desktop application, or a pinning service, IPFS makes it easy to access decentralized content. The most important thing is the CID—the unique identifier that points to the content, ensuring that you always retrieve the correct file from the network.
Amidst the challenges of data security, privacy, and accessibility, IPFS emerges as a transformative force, redefining how we store and share information in the digital age. It is a radical rethinking of how we manage data in an increasingly digital world. By decentralizing the storage and retrieval of data, IPFS mitigates risks associated with centralized servers, such as downtime.
With the growing need for security, transparency, and accessibility in the digital age, IPFS is proving to be a powerful tool for individuals, businesses, and entire industries. As the world moves toward more distributed models, technologies like IPFS will play an essential role in creating a more resilient, private, and secure internet. Embracing the decentralized web opens new possibilities for innovation, collaboration, and freedom in the way we share and consume information.