
A indústria de tecnologia da informação está em constante evolução. Percorremos um longo caminho desde aplicações de mainframe e bancos de dados relacionais até SaaS e aplicações móveis. Cada um desses desenvolvimentos ofereceu vantagens competitivas significativas para as organizações. Agora, a inteligência artificial está sendo saudada como a próxima inovação importante da indústria. Nos últimos anos, as organizações têm corrido para adotar soluções de IA para manter sua vantagem competitiva no mercado e manter intacta sua capacidade de oferecer serviços incomparáveis.
A IA pode oferecer insights inteligentes, ajudar as organizações a tomar decisões mais informadas, aumentar muito a eficiência operacional e muito mais. Na verdade, uma pesquisa recente conduzida pela ManageEngine descobriu que 86% das organizações aumentaram o uso de IA nos últimos dois anos. Empresas em todo o mundo têm grandes esperanças nas soluções de IA. No entanto, como acontece com qualquer tecnologia, existem desafios para sua implementação e desempenho.
Preocupações regulatórias atrapalham o progresso da IA
Um dos principais problemas com iniciativas de IA corporativa é a necessidade de agregar grandes quantidades de dados “limpos” de diversas fontes confiáveis e agrupar esses dados em um servidor central, mas esses requisitos levantam vários desafios. Para começar, os órgãos reguladores de privacidade de dados em todo o mundo expressaram preocupações em relação ao compartilhamento, uso e práticas de armazenamento de dados. Quase todas as nações já implementaram ou estão em processo de implementação de regulamentos de privacidade que têm efeitos de longo alcance nas práticas de gerenciamento de dados das organizações.
Os regulamentos de privacidade existentes, como o GDPR e o CCPA, também estão em constante evolução para acomodar as demandas de um mundo cada vez mais preocupado com a privacidade. Considere o escudo de privacidade UE-EUA, por exemplo, o escudo de privacidade permitiu que organizações dos Estados Unidos da América e da União Europeia transferissem dados pessoais entre si. No entanto, este escudo de privacidade UE-EUA foi invalidado pelo Tribunal de Justiça Europeu em julho de 2020 com base na proteção inadequada da privacidade.
A maioria dos regulamentos de privacidade de dados também tem requisitos de residência e localização de dados. Isso significa que os dados pessoais precisarão permanecer na mesma jurisdição onde foram criados e não podem ser transferidos para nenhum outro lugar. Isso apresenta desafios significativos para o desenvolvimento de modelos de IA, cujo desempenho depende desses mesmos dados.
A privacidade desde o início está se tornando uma obrigação
Com o surgimento dessas regulamentações de privacidade, incorporar a privacidade a todas as operações e fluxos de trabalho de sua organização não é apenas ético, mas também ajudará sua empresa a obter uma vantagem competitiva sobre as outras. Há uma nova geração de soluções chamadas de tecnologias de aprimoramento de privacidade (PETs) que são projetadas para ajudar as organizações a minimizar seu risco de privacidade e garantir que suas práticas de gerenciamento de dados não estejam infringindo nenhuma lei.
Os PETs permitem que as empresas aproveitem as quantidades cada vez maiores de dados, garantindo que as informações pessoais permaneçam privadas. Para projetos de IA, as organizações podem treinar com segurança seus modelos em dados confidenciais com a ajuda de PETs.
Um PET que leva o aprendizado de máquina tradicional um passo adiante é o aprendizado federado.
Os modelos de aprendizado de máquina padrão exigem que os dados sejam centralizados em um servidor ou datacenter. Todo o processo de treinamento do modelo e análise dos dados normalmente ocorre neste servidor central. Por exemplo, se uma organização de comércio eletrônico deseja prever a propensão de seus clientes a comprar um produto específico, ela treinará seu modelo com base nos dados coletados do site e da aplicação.
Ele pode coletar milhares de pontos de dados sobre seus clientes, como produtos comprados com mais frequência, tempo gasto em páginas de produtos, produtos adicionados a listas de desejos e muito mais. Esse conjunto de dados é então realimentado para o servidor central, onde é processado e usado para construir modelos preditivos. Quando o modelo está pronto, ele é enviado de volta aos aparelhos para mostrar as previsões para as quais foi feito. A desvantagem desse processo de ida e volta é que ele pode limitar a capacidade do modelo de aprender em tempo real. Frequentemente, também exige que dados confidenciais sejam enviados a um local diferente (o do servidor central).
Esses desafios são enfrentados pela aprendizagem federada. O aprendizado federado pega o modelo de machine learning e o leva para a borda da rede.
Compreendendo a aprendizagem federada
Na aprendizagem federada, o modelo é baixado no dispositivo de ponta, como telefones celulares, que então desenvolve um modelo atualizado usando dados coletados pelo próprio dispositivo local. O dispositivo de borda essencialmente melhora o modelo, aprendendo com os dados que ele coletou. Isso ocorre em vários dispositivos de borda, cada um calculando sua própria versão do modelo atualizado. Esses modelos treinados localmente são então enviados dos dispositivos de volta ao servidor central onde são agregados. Finalmente, um único modelo global consolidado e aprimorado é enviado de volta aos dispositivos.
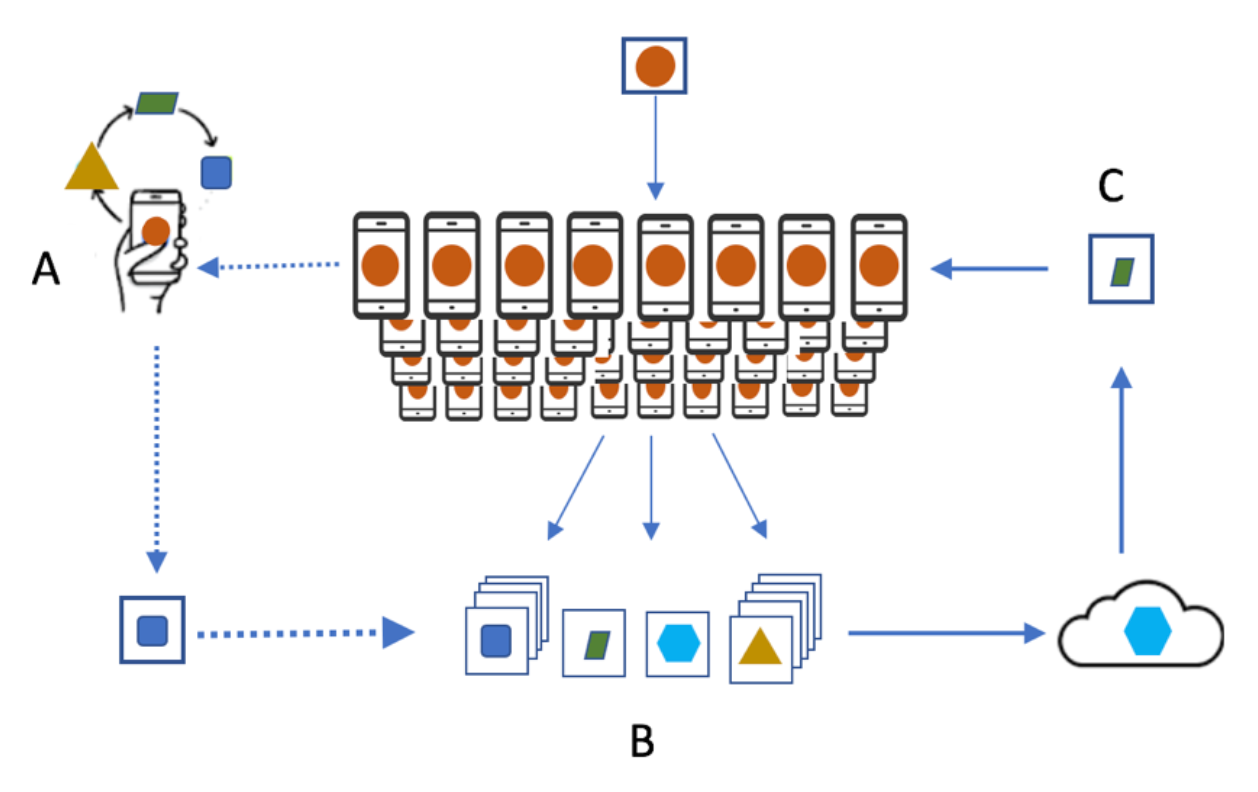
Isso significa que, em vez de ser limitado a grandes máquinas centrais, o modelo é distribuído em dispositivos móveis para computação em tempo real. O aprendizado federado permite que algoritmos de aprendizado de máquina aprendam com uma ampla variedade de conjuntos de dados provenientes de diferentes locais. Essa abordagem também possibilita que várias organizações colaborem sem a necessidade de compartilhar dados confidenciais diretamente entre si. Os dados brutos de treinamento sempre permanecem no dispositivo do usuário e nenhuma atualização individual é armazenada de forma identificável na nuvem.
Conforme várias iterações de treinamento ocorrem, os modelos compartilhados podem treinar em uma gama de dados significativamente mais ampla do que aquela que uma única organização pode possuir internamente. Em outras palavras, o aprendizado federado descentraliza o machine learning, eliminando a necessidade de agregar dados em um único local.
Essa descentralização permite implementação e testes mais rápidos, diminui a latência e diminui o consumo de energia, garantindo a privacidade. Além disso, o modelo local aprimorado no dispositivo de borda pode ser usado imediatamente, potencializando experiências personalizadas pelos dados que o dispositivo móvel coleta.
Casos de uso em tempo real de aprendizagem federada
O aprendizado federado realmente leva a IA para sua próxima geração. O cenário empresarial hoje é limitado por sua incapacidade de treinar modelos de ML em dados gerados pelo usuário. As organizações precisam confiar em dados sintéticos, que raramente são uma representação precisa de dados do mundo real.
Com o aprendizado federado, os modelos agora podem ser construídos sobre grandes quantidades de dados em tempo real sem a necessidade de se preocupar com o aspecto da privacidade, já que os dados brutos nunca saem do dispositivo de borda. Isso, por sua vez, também aborda questões éticas de IA, pois as organizações podem ir além de seus limites de dados e colaborar com diversas fontes de dados.
Isso beneficia enormemente os setores, como o de saúde, que estão sujeitos a restrições de privacidade estritas, dada a natureza dos dados com os quais operam. Portanto, as organizações de saúde podem colaborar para construir modelos inteligentes treinados com base em dados coletados de várias organizações.
Uma das maiores aplicações potenciais de aprendizagem federada pode ser encontrada em aplicações de saúde do consumidor. Com o aumento da Internet of Medical Things, houve um boom no uso de wearables e aplicações de saúde. Com muitas grandes marcas fabricando rastreadores de saúde cardíaca, rastreadores de qualidade do sono, sistemas de detecção de quedas e soluções de emergência SOS como os principais produtos de seu portfólio, o aprendizado federado pode aprimorar o funcionamento desse segmento sem arriscar a segurança das informações pessoais de saúde.
Outro exemplo de indústria que lida com informações altamente sigilosas é o setor financeiro. Veja o exemplo de uma agência de pontuação de crédito. Várias instituições financeiras, como bancos, emissores de cartão e empresas de financiamento de automóveis, enviam dados de pessoas para agências de pontuação de crédito para solicitar suas pontuações de crédito. Essas pontuações de crédito são então usadas para avaliar o risco de inadimplência de um consumidor, determinar se o crédito deve ser estendido ao consumidor e assim por diante.
Esse processo também exige que informações financeiras confidenciais sejam compartilhadas entre as organizações. No entanto, em vez de as instituições financeiras enviarem dados às agências de pontuação de crédito, as agências podem empregar o aprendizado federado para gerar as pontuações de crédito dos consumidores. As agências podem, portanto, criar um modelo de pontuação de crédito único e holístico, sem ter que acessar os dados do consumidor.
Dada a era de explosão de dados em que vivemos, as aplicações do aprendizado federado podem ser muitas e variadas. Para o roadmap corporativo, esta nova tecnologia apresenta uma bela oportunidade para democratizar a IA. Ele também abre novos caminhos para novas aplicações e fornece uma nova maneira de resolver problemas de ML em grande escala. Em um mundo onde a hiperpersonalização e as recomendações altamente contextuais ajudarão a diferenciar as empresas, o aprendizado federado terá um papel vital no futuro.
