Earlier, I introduced the eight KPIs that are critical to every IT help desk. These KPIs help meet basic IT help desk objectives such as business continuity, organizational productivity, and delivery of services on time and within budget. The previous blog post discussed the KPI change success rate. This post discusses the third KPI: infrastructure stability.
Definition: A highly stable infrastructure is characterized by maximum availability, very few outages, and low service disruptions.
Goal: Maintain a highly stable infrastructure.
To effectively gauge and monitor infrastructure stability, IT help desks need to monitor the following:
-
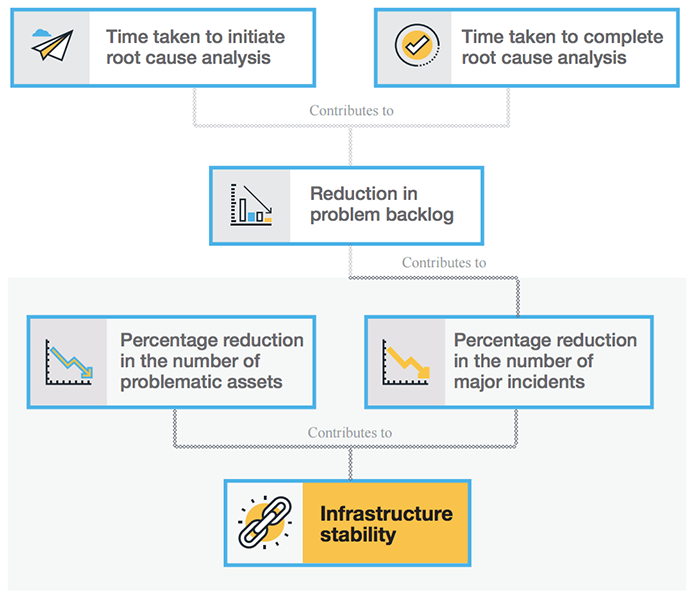
Percent reduction in the number of problematic assets
-
Percent reduction in the number of major incidents
Infrastructure stability: Percent reduction in the number of problematic assets
Delivering maximum availability and better service quality will be impossible in an infrastructure where routers have to be restarted multiple times a day, servers are often down, or workstations have to be rebooted every now and then. Therefore, such problematic assets must be identified and replaced to ensure business continuity. A problematic asset might repeatedly be the cause of service disruptions or outages, and for reporting purposes, these could be assets that have more than a couple incidents associated with them. The percent reduction in the number of problematic assets can be calculated using the following formula:
Number of problematic assets replaced at the end of the time frame ÷ Number of problematic assets identified at the beginning of the time frame
Infrastructure stability: Percent reduction in the number of major incidents
Another major indication of stability is the recurrence of major incidents on the IT infrastructure, which can lead to service disruptions or service level deterioration. A major incident, by definition, is a high-impact, high-urgency incident that affects a large number of users, depriving the business of one or two key services. The goal is to reduce the number of major incidents, which can be achieved with efficient root cause analysis (RCA) and a reduction of problem backlog. Identifying root causes and fixing problems can reduce the recurrence of major incidents and, subsequently, ticket volumes to the IT help desk.
Tips to reduce problem backlog (and therefore major incidents)
-
Faster initiation of RCA: In this case, the sooner the better. The sooner RCA is initiated, the greater the chance of identifying the root cause.
-
Quick completion of investigations: If the root cause is identified faster, the IT team can fix and resolve the problem faster, making sure that incidents don’t reoccur.
Teams can also measure these action items with details on time taken to initiate RCA after problem identification and time taken to complete RCA.
The major reasons for a heavy problem backlog could be:
-
Delayed and long-pending RCA.
-
Inconsistent quality of RCA, and lack of proper documentation.
-
Not effectively communicating the investigation process to stakeholders.
Without identifying and rectifying the root cause, the chances of major incidents recurring are fairly high. Thankfully, though, the problem backlog can be reduced by:
-
Having a dedicated problem management team with problem administrators and problem managers.
-
Identifying and training subject-matter experts.
-
Training the problem management team on basic and advanced RCA techniques.
Working on these two simple metrics—percent reduction in the number of major incidents and percent reduction in the number problematic assets—can help you maintain a highly stable IT infrastructure.
Case study: Reducing major incidents helps improve IT stability
One of the world’s leading financial institutions was able to improve its stability by reducing the number of major incidents. This reduction in the number of incidents was achieved by improving the company’s RCA process.

If you have any questions, please feel free to post them in the comments section below. In the next blog, we will discuss the next KPI, ticket volume trends. Meanwhile, if you are looking for an end-to-end IT service management solution, we encourage you to check out ServiceDesk Plus, IT help desk software trusted by over 100,000 help desks worldwide.