
Si vous ûˆtes propriûˋtaire d’une entreprise, vous connaissez la valeur d’un rûˋseau sain et vous savez û quel point une panne de rûˋseau est prûˋjudiciable û votre activitûˋ. Mais les problû´mes de rûˋseau sont inûˋvitables. La forte dûˋpendance û l’ûˋgard des rûˋseaux pour rûˋpondre û l’ûˋvolution constante des besoins des clients et de l’utilisation interne pû´se lourdement sur le rûˋseau.
Cela rend les rûˋseaux vulnûˋrables aux problû´mes courants tels que les temps d’arrûˆt soudains et imprûˋvus, l’utilisation ûˋlevûˋe des ressources et les dysfonctionnements matûˋriels.
Les goulets d’ûˋtranglement ne sont donc pas nouveaux pour un rûˋseau, mais la clûˋ rûˋside dans la faûÏon dont vous attûˋnuez la frûˋquence des problû´mes.
Deux domaines d’action pour rûˋduire les problû´mes de rûˋseau
- Le temps moyen de rûˋparation (MTTR) : Il s’agit d’une mesure du temps moyen nûˋcessaire pour rûˋparer une panne et rûˋtablir le rûˋseau û la normale. Une valeur MTTR ûˋlevûˋe peut vous nuire financiû´rement et vous obliger û payer des pûˋnalitûˋs pour non-respect des accords de niveau de service. Il est donc essentiel de disposer d’un systû´me de gestion des pannes de rûˋseau efficace et robuste.
- Trouver la cause primaire : Les rûˋseaux sont des systû´mes compliquûˋs composûˋs d’une grande variûˋtûˋ de dispositifs et d’interfaces, ce qui rend trû´s difficile pour les administrateurs rûˋseau de localiser prûˋcisûˋment la cause primaire des goulets d’ûˋtranglement du rûˋseau. Le temps ûˋcoulûˋ pour localiser les problû´mes de rûˋseau signifie que le MTTR de votre rûˋseau est en constante augmentation, ce qui peut affecter votre activitûˋ û terme.
La voie û suivre : L’analyse des causes primaires dans la surveillance du rûˋseau
L’identification des problû´mes est le plus grand dûˋfi û relever lorsqu’on essaie de rûˋduire le MTTR. Le maintien d’un MTTR faible permet de conserver la confiance des clients dans votre entreprise, et de protûˋger votre entreprise de l’effondrement.
Afin de vous permettre d’analyser en dûˋtail les performances du rûˋseau, nous avons introduit la fonction d’analyse des causes primaires (RCA) dans OpManager.
GrûÂce û la fonction RCA, vous pouvez obtenir une visibilitûˋ complû´te des donnûˋes de surveillance du rûˋseau de tous vos appareils, interfaces et URL dans une console centralisûˋe.
GrûÂce û une visibilitûˋ complû´te des informations de surveillance pertinentes, le temps nûˋcessaire û l’analyse des performances et û la dûˋtermination de la cause primaire est considûˋrablement rûˋduit, ce qui se traduit par une valeur MTTR globale plus faible.
Fonctionnalitûˋs importantes
Comparez les moniteurs graphiquement
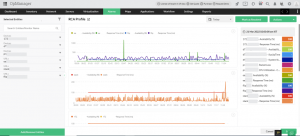
Il suffit de faire glisser et de dûˋposer les mesures de performance des dispositifs, interfaces ou URL sûˋlectionnûˋs pour que RCA construise automatiquement un graphique avec des courbes de performance, chacune reprûˋsentant un moniteur. Comparez les performances de plusieurs pûˋriphûˋriques sur une seule mesure, ou plusieurs mesures pour un seul pûˋriphûˋrique, le tout dans une seule vue.
Enregistrez vos interprûˋtations
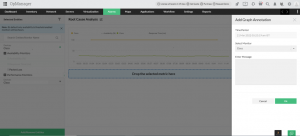
Pour trouver la cause primaire, il faut rassembler les donnûˋes de surveillance nûˋcessaires, les comparer et les analyser en dûˋtail, et enfin enregistrer vos interprûˋtations. GrûÂce û l’option d’annotation, vous pouvez enregistrer vos rûˋsultats et ajouter des notes de rûˋsolution une fois que vous avez trouvûˋ la cause racine. Si vous souhaitez interrompre votre analyse û mi-chemin, vous pouvez enregistrer vos interprûˋtations jusqu’û ce point et les sauvegarder.
Lorsque vous revenez, vous pouvez reprendre û partir du point oû¿ vous vous ûˆtes arrûˆtûˋ. Cela est ûˋgalement trû´s utile lorsque plusieurs membres de l’ûˋquipe collaborent û la recherche de la cause primaire. Par exemple, un administrateur rûˋseau peut effectuer un RCA et enregistrer ses conclusions, et plus tard, un responsable de haut niveau peut lire les notes d’annotation et prendre des dûˋcisions basûˋes sur des donnûˋes pour modifier la configuration du rûˋseau.
Effectuer un RCA pour des groupes
Cette option est utile pour analyser collectivement les performances d’un ensemble de pûˋriphûˋriques ou d’interfaces. Par exemple, lorsqu’un rûˋseau particulier dans un site spûˋcifique tombe en panne, vous pouvez sûˋlectionner le rûˋseau (groupe), ce qui fait apparaûÛtre automatiquement les pûˋriphûˋriques spûˋcifiques û ce groupe, et vous pouvez commencer û analyser les problû´mes de performance immûˋdiatement.
Comment le RCA simplifie-t-il la surveillance du rûˋseau?
Sans RCA, l’identification de la cause primaire est un vûˋritable casse-tûˆte. Par exemple, imaginez qu’une alarme soit dûˋclenchûˋe lorsqu’un routeur central de votre rûˋseau tombe en panne. Vous devez examiner en dûˋtail les donnûˋes de l’alarme et visiter la page d’instantanûˋ de l’appareil pour mieux comprendre le problû´me.
Cette mûˋthode peut sembler simple lorsque vous devez effectuer une analyse des causes primaires pour un seul appareil. Mais que se passe-t-il si plusieurs appareils de votre rûˋseau tombent en panne et que cela entraûÛne une dûˋfaillance complû´te du rûˋseau ?
Avec RCA, vous pouvez afficher les graphiques de performance de divers moniteurs dans un module centralisûˋ et les comparer tous dans un seul volet. Avec un ensemble complet d’informations sur votre ûˋcran, l’analyse des performances et la localisation de la cause premiû´re d’un problû´me deviennent une tûÂche facile.
RCA gagne du terrain : Un cas d’utilisation rûˋel
Disons que les utilisateurs signalent une vitesse de chargement lente lorsqu’ils accû´dent û votre application. Pour rûˋsoudre complû´tement le problû´me, vous devez identifier la cause rûˋelle et prendre des mesures correctives.
Tout d’abord, vous pouvez suivre l’utilisation du processeur et de la mûˋmoire de votre serveur d’application pour comprendre si la lenteur du chargement est due û une surcharge du serveur. En ûˋcartant cette possibilitûˋ, vous pourrez analyser les autres causes possibles.
Une vitesse de chargement lente peut ûˋgalement survenir lorsque votre serveur d’applications attend le pûˋriphûˋrique de stockage qui abrite votre systû´me de fichiers. Vous pouvez vûˋrifier les IOPS, la latence, le dûˋbit et l’utilisation de votre pûˋriphûˋrique de stockage pour comprendre si le problû´me est dû£ û un pûˋriphûˋrique de stockage sous-performant et sur-utilisûˋ.
Parfois, la lenteur du chargement peut ûˋgalement ûˆtre due û des problû´mes de bande passante dans les interfaces reliant le serveur et votre environnement de stockage. La surveillance des mûˋtriques Interface Rx et Interface Tx vous aidera û localiser les goulots d’ûˋtranglement, le cas ûˋchûˋant.
Ainsi, lorsque vous rencontrez un scûˋnario complexe tel que celui ûˋvoquûˋ ci-dessus, vous devrez comparer les performances de plusieurs composants rûˋseau. RCA fournit la plateforme permettant de rassembler toutes les donnûˋes en une seule vue, de les analyser, d’ûˋcarter les possibilitûˋs et de dûˋterminer la cause exacte des problû´mes en moins de temps.
Apprenez-en davantage sur OpManager et tûˋlûˋchargez une version d’essai gratuite de 30 jours. Vous pouvez ûˋgalement faire l’expûˋrience d’une dûˋmo gratuite en ligne, ou programmer une dûˋmo gratuite et personnalisûˋe avec nos experts qui pourront rûˋpondre û toutes vos questions sur le produit.
Sourceô : Bolster network monitoring with root cause analysis
